
Automatically sort and rename scanned PDF documents
Document classification is a big challenge for many decades in almost all industries, and it has a very important necessity in various business processes. Traditionally, this process is being done manually, like users read the document and identify the subject to classify the documents. Even though the manual process helps categorizing more precisely, it is largely time-consuming and very expensive.
The digitizing of business processes has reduced significant manual efforts over time which has resulted in faster growth of economies. There are many document work automation tools and services that are already available in the market which can ease the business processes to be faster and easily scalable. As part of this, organizing large volumes of documents that come into your business process needs to be faster. The process of sorting and organizing can be done automatically with supporting features using the PDF4me Workflow feature.
For your better understanding, we have taken a specific use case
- Find Invoice Number from the document using regular expressions and rename the file with invoice number, and explained step by step in detail.
3 Easy Steps to sort your documents, rename them, and save them to well-sorted storage.
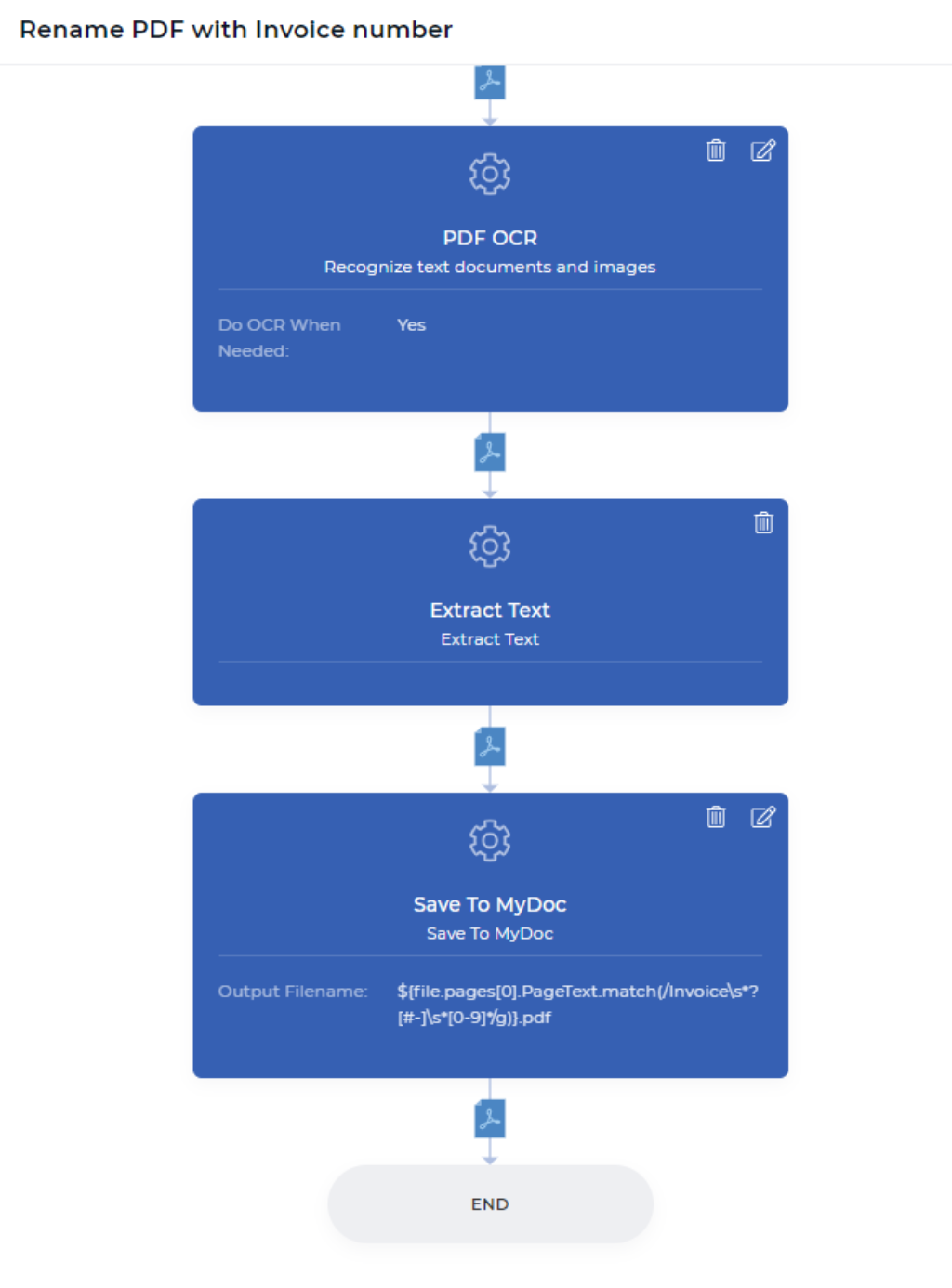
Step 1: Do OCR only when needed
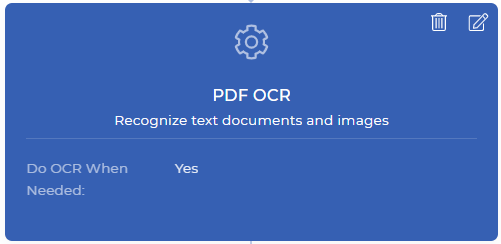
This would be the very first step of your workflow action from PDF4me. The PDF OCR action is a powerful feature, that could detect whether your input document is a scanned document or text-based document, and apply OCR only when needed. Usually, OCR is a bit costlier than other features as it involved dedicated resources packed with powerful OCR engines and related components.
In the automation workflow, there might be situations where you may need OCR sometimes when the document is a scanned image. You don’t need to pay unnecessarily when you don’t really need to apply OCR when your document has no scanned image. Just enable the option “Do OCR When Needed” while adding OCR action in your workflow. This action produces a text-based PDF file after conversion or returns the same file when it doesn’t require conversion.
Step 2: Extract text from each page of your PDF document
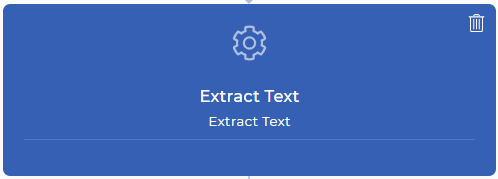
Extract Text workflow action will bring all your page content to your next action data context. This means you can play with your content however you want - like parse particular text, check if your desired text is found, combine your parsed text with your custom text, and many more with JavaScript expressions. In this example, will be trying to find the invoice number from an online paid receipt.
Sample invoice PDF:

From this PDF file we want to parse the invoice number and using this number we will rename the file and store it in PDF4me’s My Docs cloud storage finally.
The output data context of this action will contain the text in the below format.
${file.pages[0].PageText}
[0] - this indicates the page number starting from zero, this can be set to any number to get the page text from any page range of your PDF document.
Append regular expression to find a match from the PageText data context as below.
${file.pages[0].PageText.match(/Invoice\s*?[#-]\s*[0-9]*/g)}
This is a simple JavaScript function to apply regular expression along with your data context results. This regex trying to find the invoice number along with the Invoice label.
Like this, you can make use of JavaScript functions to apply any logical functions to identify your document and make a decision to classify it more accurately and without any manual efforts.
Step 3: Rename and save it to My Document Storage
Save To MyDoc is a PDF4me action, that lets you save your document in PDF4me storage. If you want to store this in your Dropbox, FTP, or Google Drive is also possible. For the demonstration purpose, we use My Docs storage for now. All save to actions has Output Filename, which is a non-mandatory field.
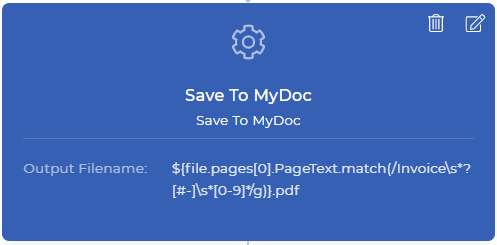
You can set your custom filename with any dynamic combination like ${INV}-{UTCNOW()}.pdf - This will produce documents prefixed as INV- and suffixed current UTC time dynamically. You get control over what to how to store and where to store your output documents. In our demonstration use case, we need to place the data context along with regular expression to generate a new file name just like below.
${file.pages[0].PageText.match(/Invoice\s*?[#-]\s*[0-9]*/g)}.pdf
After executing all these tree steps your document will be classified, renamed, and stored with your desired file storage location. How easy is this for you now? Yes, PDF4me always thinks from an end-user perspective and makes their life so easy in the world of document processing.


