
Automatisches Sortieren und Umbenennen gescannter PDF-Dokumente
Die Klassifizierung von Dokumenten ist seit vielen Jahrzehnten eine große Herausforderung in fast allen Branchen, und sie ist eine wichtige Voraussetzung für verschiedene Geschäftsprozesse. Traditionell wird dieser Prozess manuell durchgeführt, d. h. die Benutzer lesen das Dokument und identifizieren das Thema, um die Dokumente zu klassifizieren. Obwohl der manuelle Prozess zu einer genaueren Kategorisierung beiträgt, ist er sehr zeitaufwändig und teuer.
Die Digitalisierung von Geschäftsprozessen hat im Laufe der Zeit den manuellen Aufwand erheblich reduziert, was zu einem schnelleren Wachstum der Wirtschaft geführt hat. Auf dem Markt sind bereits zahlreiche Tools und Dienste zur Automatisierung der Dokumentenverarbeitung erhältlich, die die Geschäftsprozesse beschleunigen und leicht skalierbar machen können. Dazu gehört auch die schnellere Organisation großer Mengen von Dokumenten, die in Ihren Geschäftsprozessen anfallen. Der Prozess des Sortierens und Organisierens kann mit Hilfe der Funktion PDF4me Workflow automatisch mit unterstützenden Funktionen durchgeführt werden.
Zu Ihrem besseren Verständnis haben wir einen konkreten Anwendungsfall gewählt
- Finden Sie die Rechnungsnummer aus dem Dokument mit regulären Ausdrücken und benennen Sie die Datei mit der Rechnungsnummer um, und erklärt Schritt für Schritt im Detail.
3 einfache Schritte, um Ihre Dokumente zu sortieren, umzubenennen und geordnet zu speichern.
Schritt 1: OCR nur bei Bedarf durchführen
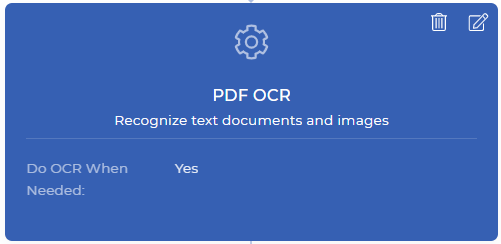
Dies wäre der erste Schritt Ihrer Workflow-Aktion von PDF4me. Die PDF OCR-Aktion ist eine leistungsstarke Funktion, die erkennen kann, ob es sich bei Ihrem Eingabedokument um ein gescanntes oder ein textbasiertes Dokument handelt, und die OCR nur bei Bedarf anwendet. Normalerweise ist OCR etwas kostspieliger als andere Funktionen, da sie spezielle Ressourcen mit leistungsstarken OCR-Engines und zugehörigen Komponenten erfordert.
Im Automatisierungsworkflow kann es Situationen geben, in denen Sie OCR benötigen, auch wenn das Dokument ein gescanntes Bild ist. Sie müssen nicht unnötig viel Geld ausgeben, wenn Sie die OCR nicht wirklich benötigen, wenn Ihr Dokument kein gescanntes Bild enthält. Aktivieren Sie einfach die Option “OCR bei Bedarf durchführen”, wenn Sie eine OCR-Aktion zu Ihrem Workflow hinzufügen. Diese Aktion erzeugt nach der Konvertierung eine textbasierte PDF-Datei oder gibt die gleiche Datei zurück, wenn keine Konvertierung erforderlich ist.
Schritt 2: Extrahieren von Text aus jeder Seite Ihres PDF-Dokuments
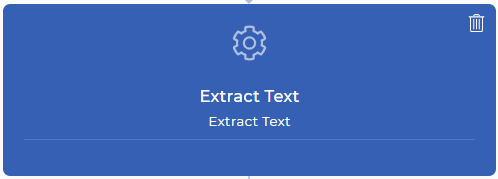
Die Workflow-Aktion Text extrahieren bringt den gesamten Inhalt Ihrer Seite in den Datenkontext der nächsten Aktion. Das bedeutet, dass Sie mit Ihrem Inhalt spielen können, wie Sie wollen - z. B. einen bestimmten Text analysieren, prüfen, ob der gewünschte Text gefunden wurde, den analysierten Text mit Ihrem eigenen Text kombinieren und vieles mehr mit JavaScript-Ausdrücken. In diesem Beispiel wird versucht, die Rechnungsnummer aus einer online bezahlten Quittung zu finden.
Musterrechnung PDF:

Aus dieser PDF-Datei wollen wir die Rechnungsnummer auslesen und anhand dieser Nummer die Datei umbenennen und schließlich in PDF4me’s My Docs Cloud-Speicher ablegen.
Der Ausgabedatenkontext dieser Aktion enthält den Text in folgendem Format.
${file.pages[0].PageText}
[0] - dies gibt die Seitennummer an, die bei Null beginnt. Sie kann auf eine beliebige Zahl gesetzt werden, um den Seitentext aus einem beliebigen Seitenbereich Ihres PDF-Dokuments zu erhalten.
Fügen Sie einen regulären Ausdruck an, um eine Übereinstimmung mit dem PageText-Datenkontext zu finden (siehe unten).
${file.pages[0].PageText.match(/Rechnung\s*?[#-]\s*[0-9]*/g)}
Dies ist eine einfache JavaScript-Funktion, um reguläre Ausdrücke zusammen mit den Ergebnissen Ihres Datenkontexts anzuwenden. Dieser reguläre Ausdruck versucht, die Rechnungsnummer zusammen mit dem Rechnungsetikett zu finden.
Auf diese Weise können Sie JavaScript-Funktionen nutzen, um beliebige logische Funktionen zur Identifizierung Ihres Dokuments anzuwenden und eine Entscheidung zu treffen, um es genauer und ohne manuellen Aufwand zu klassifizieren.
Schritt 3: Umbenennen und in My Document Storage speichern
Save To MyDoc ist eine PDF4me-Aktion, mit der Sie Ihr Dokument im PDF4me-Speicher speichern können. Wenn Sie das Dokument in Dropbox, FTP oder Google Drive speichern möchten, ist dies ebenfalls möglich. Zu Demonstrationszwecken verwenden wir vorerst den Speicher My Docs. Alle “Speichern unter”-Aktionen haben ein Feld für den Ausgabedateinamen, das nicht obligatorisch ist.
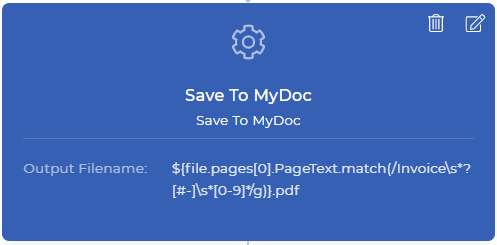
Sie können Ihren benutzerdefinierten Dateinamen mit einer beliebigen dynamischen Kombination wie ${INV}-{UTCNOW()}.pdf festlegen - dadurch werden Dokumente mit dem Präfix INV- und dem Suffix aktuelle UTC-Zeit dynamisch erzeugt. Sie haben die Kontrolle darüber, wie und wo Ihre Ausgabedokumente gespeichert werden sollen. In unserem Anwendungsfall müssen wir den Datenkontext zusammen mit einem regulären Ausdruck platzieren, um einen neuen Dateinamen zu erzeugen, wie unten dargestellt.
${file.pages[0].PageText.match(/Rechnung\s*?[#-]\s*[0-9]*/g)}.pdf
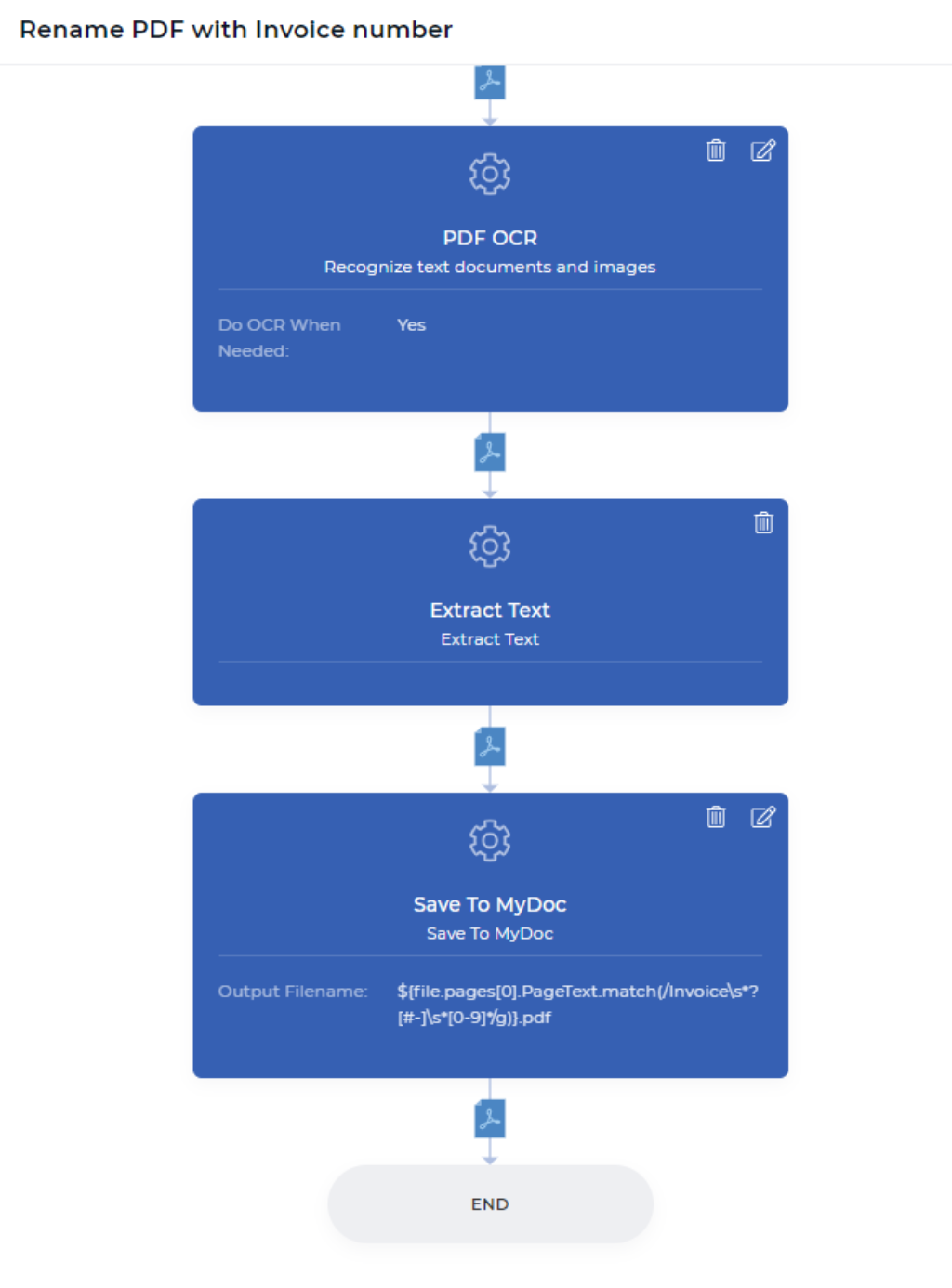
Nach Ausführung all dieser drei Schritte wird Ihr Dokument klassifiziert, umbenannt und an dem von Ihnen gewünschten Speicherort abgelegt. Wie einfach ist das jetzt für Sie? Ja, PDF4me denkt immer aus der Perspektive des Endanwenders und macht ihm das Leben in der Welt der Dokumentenverarbeitung so einfach.


