
自动分类和重命名扫描的PDF文件
文档分类是几十年来几乎所有行业的一个大挑战,它在各种商业流程中具有非常重要的必要性。传统上,这一过程是由人工完成的,比如用户阅读文件并确定主题来对文件进行分类。尽管手工过程有助于更精确的分类,但它在很大程度上是耗时和非常昂贵的。
随着时间的推移,业务流程的数字化已经减少了大量的人工工作,这导致了经济的快速增长。市场上已经有许多文件工作自动化工具和服务,可以使业务流程更快、更容易扩展。作为其中的一部分,组织进入你的业务流程的大量文件需要更快。使用PDF4me Workflow功能,分类和组织的过程可以通过辅助功能自动完成。
为了让你更好地理解,我们采取了一个具体的使用案例
- 使用正则表达式从文件中找到发票号码,并以发票号码重命名文件,并一步步详细解释。
3个简单的步骤,对你的文件进行分类,重命名,并将它们保存到分类好的存储空间。
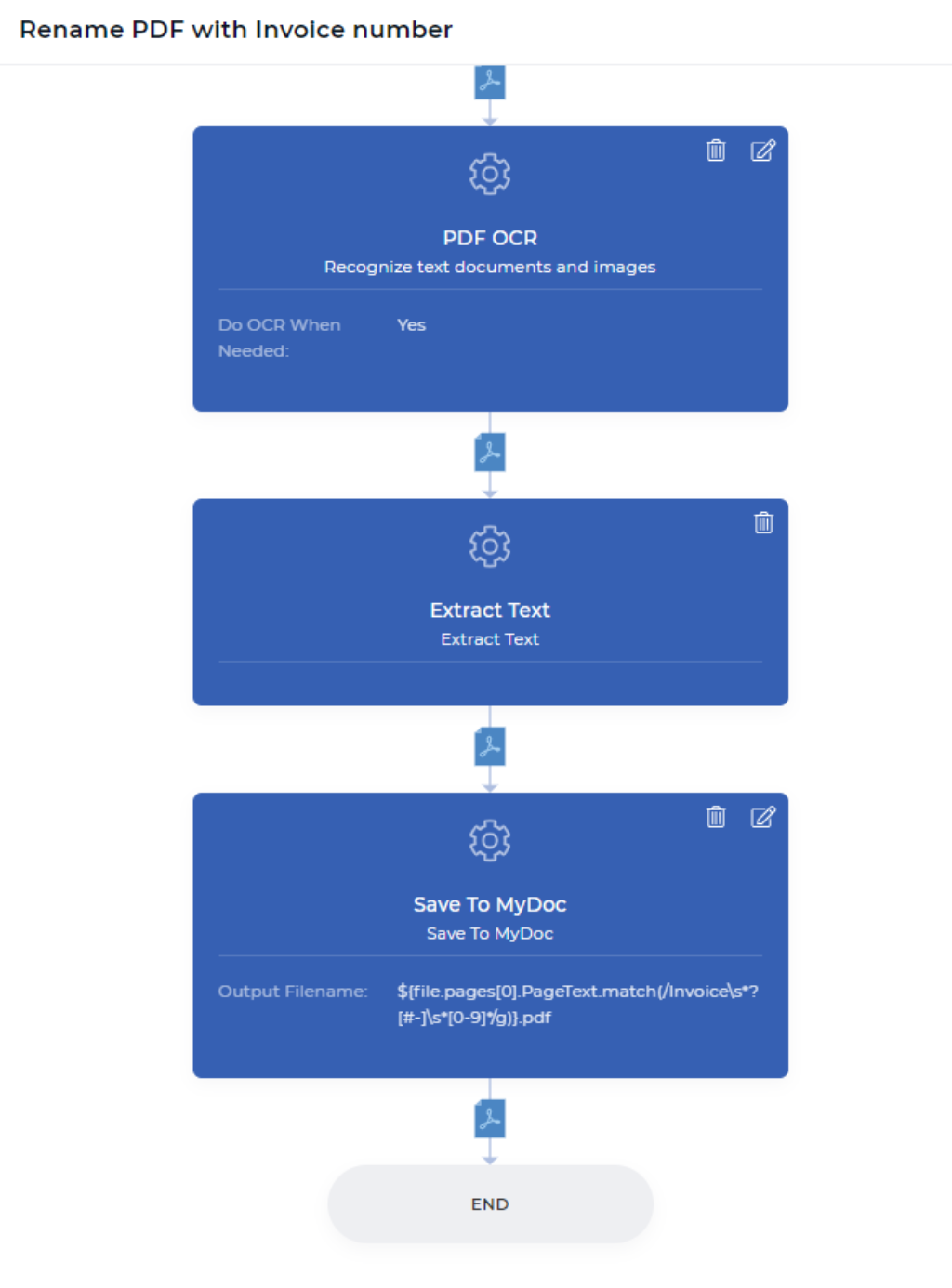
第1步:只在需要时做OCR。
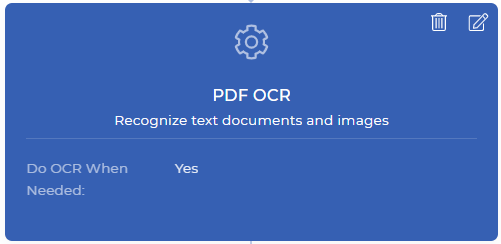
这将是你在PDF4me工作流程中的第一步。PDF OCR动作是一个强大的功能,它可以检测你的输入文件是否是扫描文件或基于文本的文件,并在需要时才应用OCR。通常情况下,OCR比其他功能的成本要高一些,因为它涉及到专用资源与强大的OCR引擎和相关组件。
在自动化工作流程中,可能会有这样的情况:当文件是扫描图像时,你有时会需要OCR。当你的文档没有扫描图像时,你不需要付出不必要的代价来应用OCR。只要在你的工作流程中添加OCR动作时启用 "需要时做OCR "选项。这个动作在转换后产生一个基于文本的PDF文件,或者在不需要转换时返回相同的文件。
第2步:从你的PDF文档的每一页提取文本
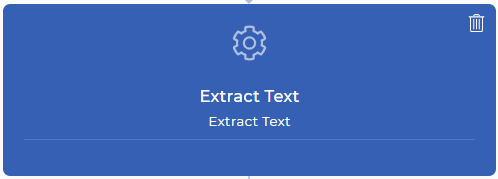
提取文本的工作流程动作将把你所有的页面内容带到你的下一个动作数据背景中。这意味着你可以随心所欲地玩弄你的内容–比如解析特定的文本,检查是否找到了你想要的文本,将你解析的文本与你的自定义文本结合起来,以及更多的JavaScript表达式。在这个例子中,将试图从一个在线支付的收据中找到发票号码。
发票样本PDF。

从这个PDF文件中,我们要解析出发票号码,利用这个号码,我们将重命名该文件,并最终将其存储在PDF4me的我的文档云存储中。
这个动作的输出数据背景将包含以下格式的文本。
``${file.pages[0].PageText}```。
[0] - 这表示从零开始的页码,这可以设置为任何数字,以便从你的PDF文档的任何页面范围获得页面文本。
添加正则表达式,从PageText数据上下文中找到一个匹配项,如下所示。
``${file.pages[0].PageText.match(/Invoice\s*?[#-]\s*[0-9]*/g)}````
这是一个简单的JavaScript函数,将正则表达式与你的数据背景结果一起应用。这个正则表达式试图找到发票号码和发票标签。
像这样,你可以利用JavaScript函数,应用任何逻辑函数来识别你的文件,并作出决定,更准确地进行分类,而不需要任何人工努力。
第3步:重命名并保存到我的文档存储中
Save To MyDoc是一个PDF4me操作,它可以让你把你的文件保存在PDF4me存储中。如果你想存储在你的Dropbox、FTP或Google Drive中也是可以的。为了演示的目的,我们现在使用我的文档存储。所有保存到行动都有输出文件名,这是一个非强制性的字段。
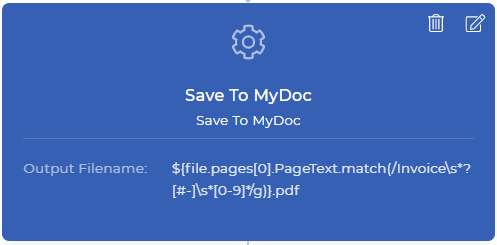
你可以用任何动态组合设置你的自定义文件名,如${INV}-{UTCNOW()}.pdf - 这将产生以INV为前缀,以当前UTC时间为后缀的动态文档。你可以控制如何存储和在哪里存储你的输出文件。在我们的示范用例中,我们需要将数据上下文与正则表达式放在一起,生成一个新的文件名,就像下面这样。
``${file.pages[0].PageText.match(/Invoice/s*?[#-]/s*[0-9]/g)}.pdf ````${file.pages[0].PageText.match(/Invoice/s?
在执行所有这些树形步骤后,你的文件将被分类、重命名,并存储在你所期望的文件存储位置。这对你来说有多容易呢?是的,PDF4me总是从最终用户的角度考虑问题,使他们在文件处理的世界里生活得如此轻松。


