
Classificar e renomear automaticamente documentos PDF digitalizados
A classificação de documentos é um grande desafio há muitas décadas em quase todas as indústrias, e tem uma necessidade muito importante em vários processos de negócios. Tradicionalmente, este processo é feito manualmente, tal como os utilizadores lêem o documento e identificam o assunto para classificar os documentos. Embora o processo manual ajude a categorizar com mais precisão, ele é em grande parte demorado e muito caro.
A digitalização dos processos de negócio reduziu significativamente os esforços manuais ao longo do tempo, o que resultou num crescimento mais rápido das economias. Existem muitas ferramentas e serviços de automação do trabalho documental que já estão disponíveis no mercado e que podem facilitar os processos de negócios para serem mais rápidos e facilmente escaláveis. Como parte disso, organizar grandes volumes de documentos que entram no seu processo de negócios precisa ser mais rápido. O processo de classificação e organização pode ser feito automaticamente com recursos de suporte usando a função [PDF4me Workflow(/pdf4me-workflows/).
Para sua melhor compreensão, tomamos um caso de uso específico
- Encontre o número da fatura do documento usando expressões regulares e renomeie o arquivo com o número da fatura, e explique passo a passo em detalhes.
3 Passos fáceis para classificar seus documentos, renomeá-los, e salvá-los para um armazenamento bem ordenado.
Passo 1: Faça OCR somente quando necessário
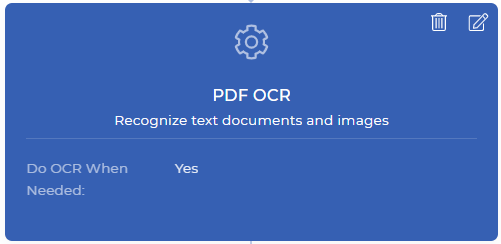
Este seria o primeiro passo da sua acção de workflow da PDF4me. A ação de OCR do PDF é um recurso poderoso, que pode detectar se o seu documento de entrada é um documento digitalizado ou baseado em texto, e aplicar OCR somente quando necessário. Normalmente, o OCR é um pouco mais caro do que outros recursos, pois envolve recursos dedicados repletos de poderosos mecanismos de OCR e componentes relacionados.
No fluxo de trabalho de automação, pode haver situações em que você pode precisar de OCR às vezes quando o documento é uma imagem digitalizada. Você não precisa pagar desnecessariamente quando não precisa realmente aplicar OCR quando seu documento não tem imagem digitalizada. Basta ativar a opção “Fazer OCR quando necessário” enquanto adiciona a ação de OCR ao seu fluxo de trabalho. Essa ação produz um arquivo PDF baseado em texto após a conversão ou retorna o mesmo arquivo quando ele não requer conversão.
Passo 2: Extrair texto de cada página do seu documento PDF
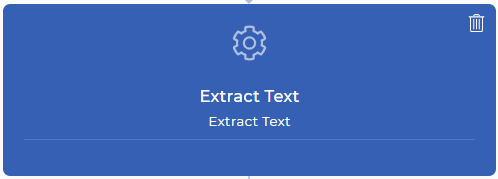
A acção Extract Text workflow trará todo o conteúdo da sua página para o seu próximo contexto de dados de acção. Isto significa que você pode jogar com seu conteúdo como quiser - como analisar um texto específico, verificar se seu texto desejado é encontrado, combinar seu texto analisado com seu texto personalizado, e muito mais com expressões JavaScript. Neste exemplo, você estará tentando encontrar o número da fatura a partir de um recibo pago online.
Exemplo de PDF de fatura:

A partir deste arquivo PDF queremos analisar o número da fatura e usando este número vamos renomear o arquivo e armazená-lo em PDF4me [My Docs(/my-doc/) cloud storage finalmente.
O contexto dos dados de saída desta acção irá conter o texto no formato abaixo.
```${file.pages[0].PageText}`````````
0]0]- isto indica o número da página começando de zero, isto pode ser definido para qualquer número para obter o texto da página de qualquer intervalo de páginas do seu documento PDF.
Anexe expressão regular para encontrar uma correspondência a partir do contexto de dados PageText como abaixo.
Esta é uma simples função JavaScript para aplicar a expressão regular juntamente com os resultados do contexto dos seus dados. Este regex tenta encontrar o número da factura junto com a etiqueta de facturação.
Assim, você pode fazer uso das funções do JavaScript para aplicar qualquer função lógica para identificar seu documento e tomar a decisão de classificá-lo com mais precisão e sem nenhum esforço manual.
Passo 3: Renomeie e salve-o no Meu Armazenamento de Documentos
Save To MyDoc* é uma acção PDF4me, que lhe permite guardar o seu documento no armazenamento PDF4me. Se você quiser armazenar isso no seu Dropbox, FTP ou Google Drive também é possível. Para fins de demonstração, usamos My Docs armazenamento por enquanto. Todos os salvamentos em ações tem nome de arquivo de saída, que é um campo não obrigatório.
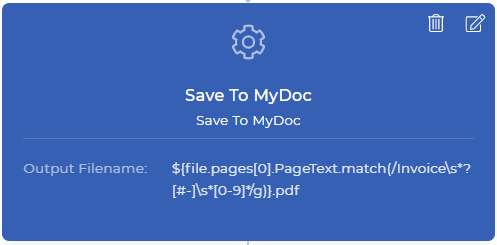
Você pode definir seu nome de arquivo personalizado com qualquer combinação dinâmica como ```${INV}-{UTCNOW()}.pdf```` - Isto irá produzir documentos prefixados como INV- e sufixados dinamicamente como tempo UTC atual. Você tem controle sobre o que armazenar e onde armazenar seus documentos de saída. No nosso caso de demonstração, precisamos colocar o contexto dos dados junto com a expressão regular para gerar um novo nome de arquivo, como abaixo.
```${{file.pages[0].PageText.match(/Invoice\s*?[#-]\s*[0-9]/g)}.pdf ````````````file.pages[0].PageText.match(/Invoice\s?[#-]^^s*[0-9]*/g)}.pdf
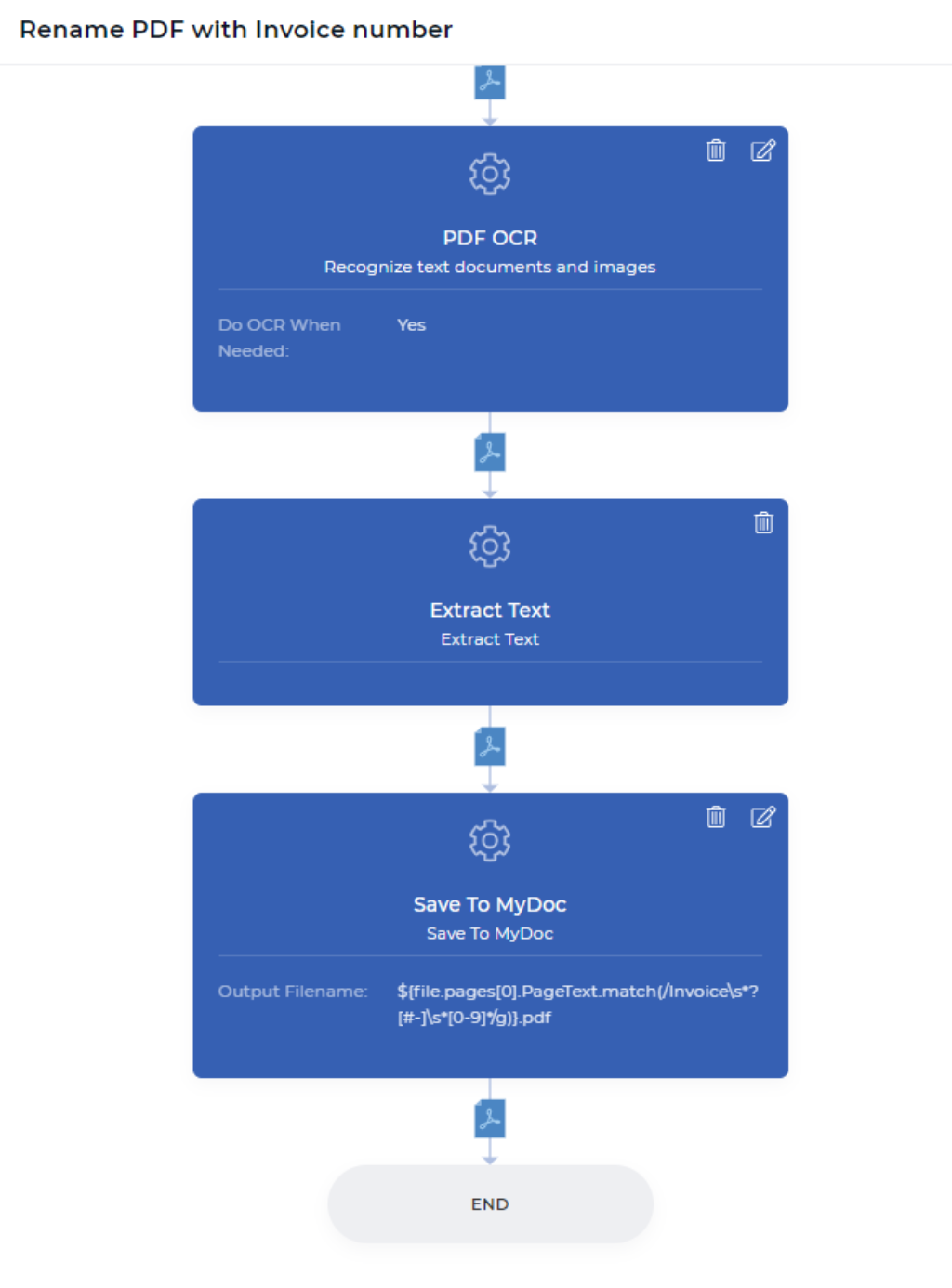
Após executar todas essas etapas em árvore, seu documento será classificado, renomeado e armazenado com o local de armazenamento do arquivo desejado. Quão fácil é isso para você agora? Sim, PDF4me pensa sempre da perspectiva do utilizador final e torna a sua vida tão fácil no mundo do processamento de documentos.


