

Advanced OCR for Images using Power Automate
We capture a lot of images of documents or surfaces with text for extracting the data or for later reference. Converting scanned documents or images as text-searchable PDF files is important for their further processing. To make PDFs searchable, the most used technology is optical character recognition - OCR.
PDF4me provides high-quality PDF OCR that produces one of the most accurate text recognition. But when you have hundreds of scanned documents that need to be recognized the only solution would be automation. PDF4me has a solution for that also.
Combined with Power Automate from Microsoft’s Power Apps, PDF4me can automate business processes involving document jobs that are mundane and time-consuming. PDF4me with Power Automate will connect you across data sources, apps, and services to easily create robust workflows to automate document jobs.
How to use OCR in Power Automate?
Let us look at an example where we can transform an image to PDF with PDF4me OCR action in Power Automate. Say we have some images of documents or images with text in OneDrive or we expect them to arrive in a specific folder. Let us convert them to PDF and perform OCR.
You can try the Image to PDF and PDF OCR tool online to see the quality of conversions.
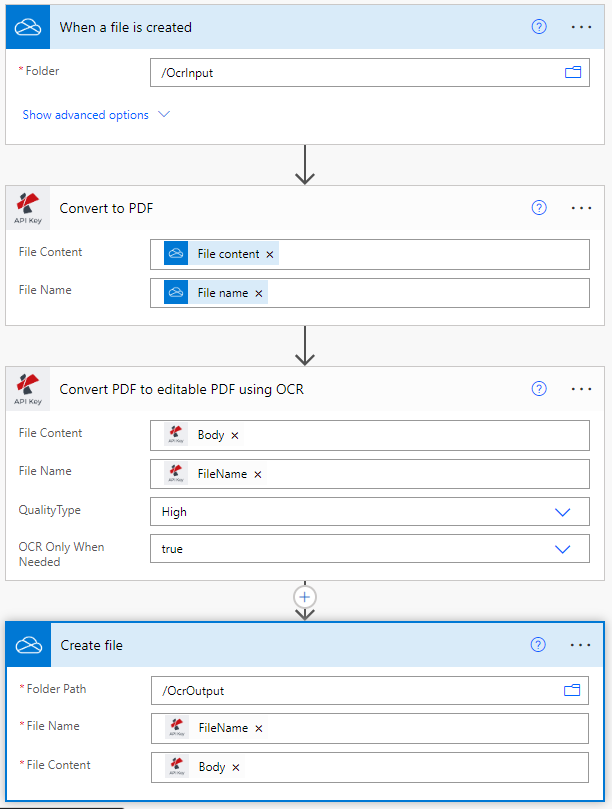
Add a trigger for OneDrive
Power Automate has multiple types of triggers to start your workflow. In this use case, add a OneDrive trigger to start the automation.
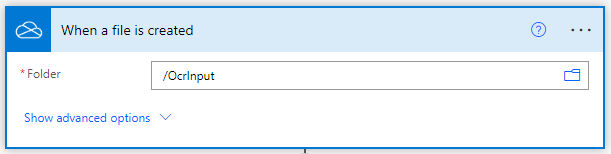
Add Convert to PDF for document images
Click on ‘New Step’ after completing the Trigger part. A prompt with many app suggestions where you have to search for PDF4me and select PDF4me Connect. From the list of Actions select the Convert to PDF action.
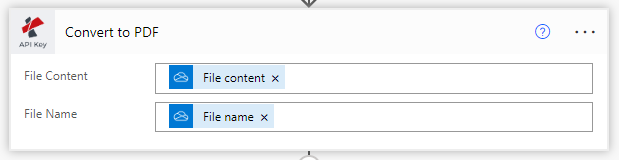
Choose Convert PDF to editable using OCR Action
From the PDF4me actions, list select PDF OCR.
File Content: Map source PDF file content from the previous action
File Name: Map source PDF file content from the previous action
Quality Type: Choose the quality type. Draft or High
PDF4me recommends High quality profile OCR for images which ensures accurate recognition even from complex images.
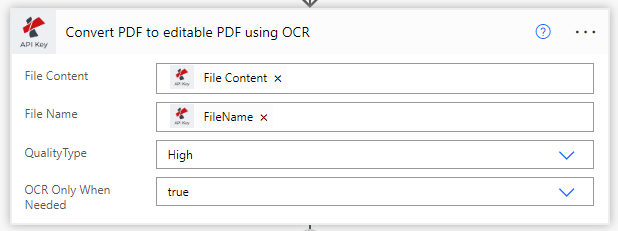
Set the ‘OCR only when required’ to true, so that the action does not perform OCR on a PDF that is already recognized. Thereby, saving call costs.
Save OCR processed files
Finally, after the OCR action add an action for storing the output PDF files to the desired storage. In the example we again use a OneDrive save action.
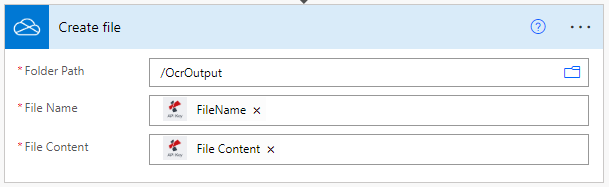
You can use also use regular expressions(RegEx) in the ‘File Name’ field to create dynamic names for better sorting of the processed documents.
Ready to use templates for OCR
To get you started quickly we have a few templates ready for you to start with.
With a PDF4me Developer Subscription, create PDF OCR workflows and more awesome automation and save valuable time to focus on the most important things.


