

Make PDFs Searchable (OCR) using Power Automate
Mankind is going through a big turning point. It’s posing a great challenge and also provides us with opportunities to change and revolutionize our life and work. We are being advised to minimize transactions that require physical contact. This applies to documents also. Scanning of physical documents for further processing or archiving is a much-sought requirement these days. Scanned documents are often generated as PDF files due to their portability. They are sometimes captured using cameras as images also.
Converting scanned documents or images as text-searchable PDF files is important for their further processing. To make PDFs searchable, the most used technology is optical character recognition - OCR. There are many software applications that boast text recognition, but it is very difficult to generate quality outputs from a scanned file, especially a scanned image. PDF4me provides high-quality PDF OCR that produces one of the most accurate text recognition. But when you have hundreds of scanned documents that need to be recognized the only solution would be automation. PDF4me has a solution for that also.
Combined with Power Automate from Microsoft’s Power Apps, PDF4me can automate business processes involving document jobs that are mundane and time-consuming. PDF4me with Power Automate will connect you across data sources, apps, and services to easily create robust workflows to automate document jobs.
Let us look at an example where you want to convert a scanned PDF document into a searchable PDF.
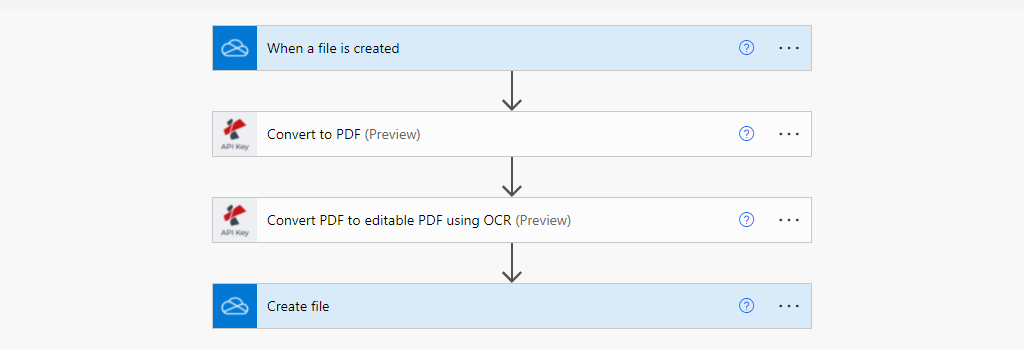
Step 1: Trigger Execution
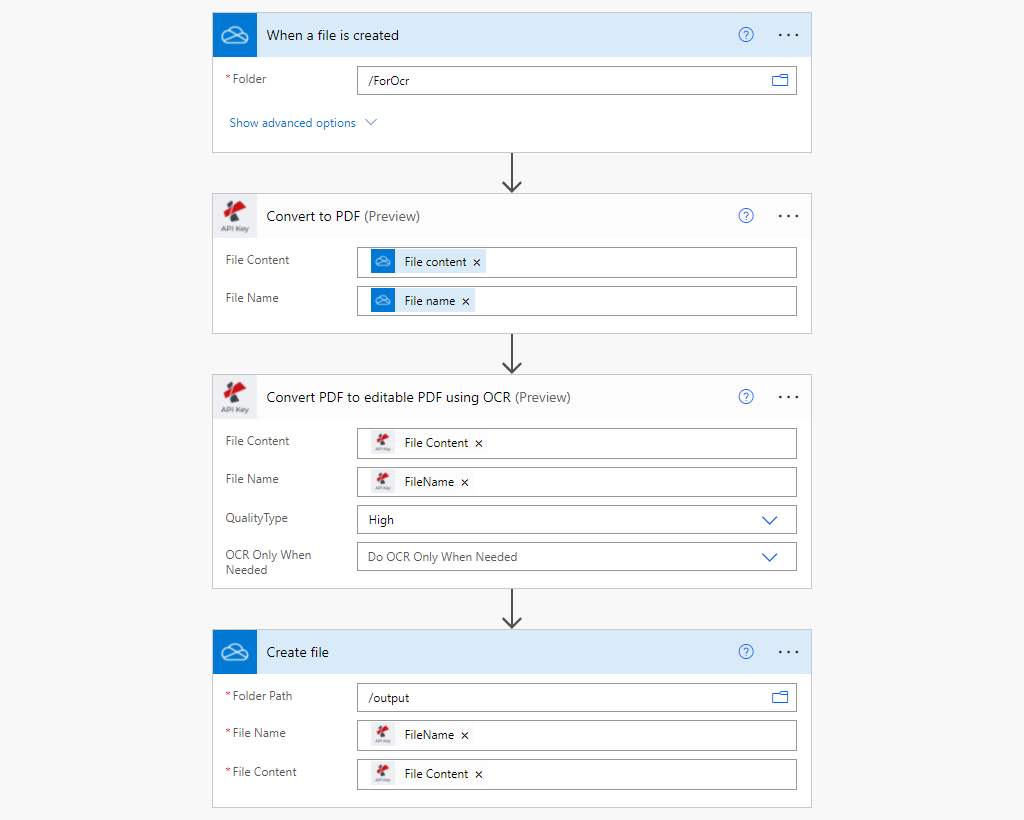
Power Automate has multiple types of triggers to start your workflow. In this use case, we trigger workflow when a file is created in the OneDrive folder location.

Step 2: Add Convert to PDF for document images
Click on ‘New Step’ after completing the Trigger part. A prompt with many app suggestions where you have to search for PDF4me and select PDF4me Connect. From the list of Actions select the Convert to PDF action.

Step 3: Choose PDF OCR Action and Map input fields
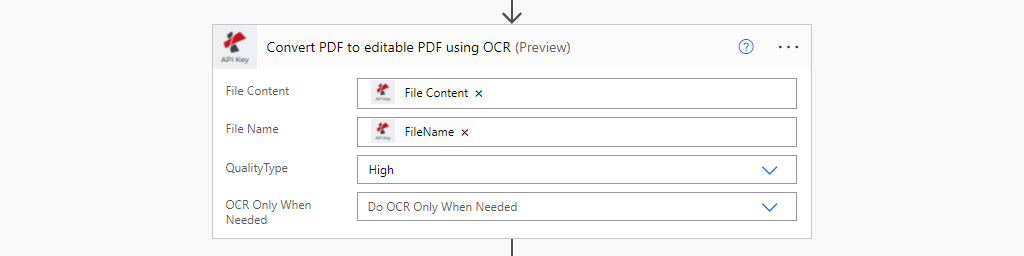
From the PDF4me actions, list select PDF OCR.
- File Content: Map source PDF file content from the previous action
- File Name: Map source PDF file content from the previous action
- Quality Type: Choose the quality type. Draft or High
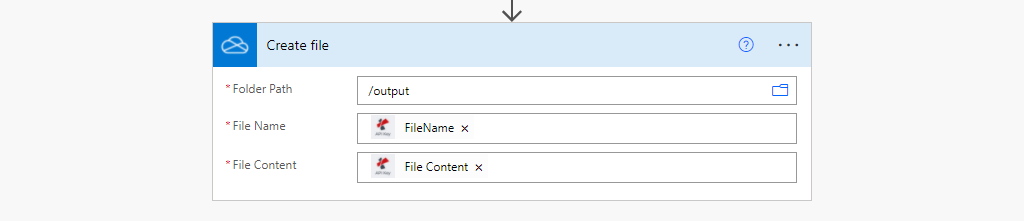
Step 4: Save OCR processed file to OneDrive location
This is a final step to save converted output files to the OneDrive folder location.
You can try the Convert to PDF and PDF OCR tool online to see the quality of conversions.
Get started
To get you started quickly we have a few templates ready for you to start with.
With a PDF4me Developer Subscription, create PDF OCR workflows and more awesome automation and save valuable time to focus on the most important things.


