

Hacer búsquedas en PDFs (OCR) usando Power Automate
La humanidad está atravesando un gran punto de inflexión. Está suponiendo un gran reto y también nos ofrece oportunidades para cambiar y revolucionar nuestra vida y nuestro trabajo. Se nos aconseja minimizar las transacciones que requieren contacto físico. Esto se aplica también a los documentos. El escaneo de documentos físicos para su posterior procesamiento o archivo es un requisito muy demandado hoy en día. Los documentos escaneados suelen generarse como archivos PDF debido a su portabilidad. A veces también se capturan mediante cámaras como imágenes.
Convertir documentos o imágenes escaneadas en archivos PDF con capacidad de búsqueda de texto es importante para su posterior procesamiento. Para hacer que los PDF se puedan buscar, la tecnología más utilizada es el reconocimiento óptico de caracteres (OCR). Hay muchas aplicaciones de software que presumen de reconocimiento de texto, pero es muy difícil generar resultados de calidad a partir de un archivo escaneado, especialmente una imagen escaneada. PDF4me ofrece un OCR para PDF de alta calidad que produce uno de los reconocimientos de texto más precisos. Pero cuando se tienen cientos de documentos escaneados que necesitan ser reconocidos, la única solución sería la automatización. PDF4me también tiene una solución para eso.
En combinación con Power Automate de Power Apps de Microsoft, PDF4me puede automatizar los procesos empresariales que implican trabajos documentales que son mundanos y que consumen mucho tiempo. PDF4me con Power Automate le conectará a través de fuentes de datos, aplicaciones y servicios para crear fácilmente flujos de trabajo robustos para automatizar trabajos de documentos.
Veamos un ejemplo en el que se desea convertir un documento PDF escaneado en un PDF con capacidad de búsqueda.
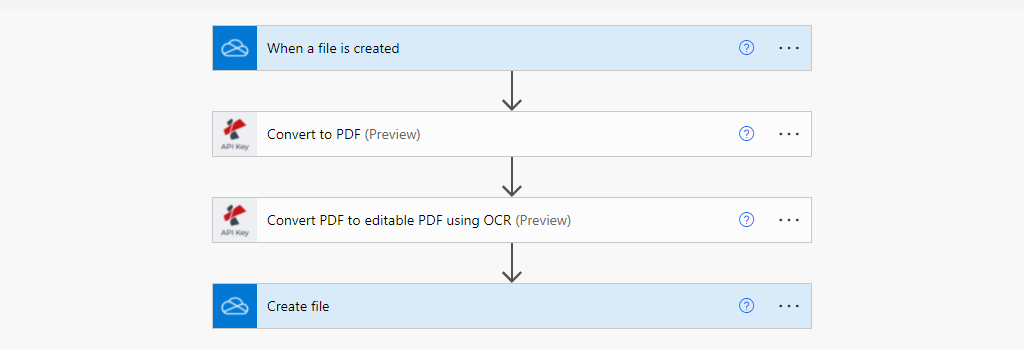
Paso 1: Ejecución de la activación
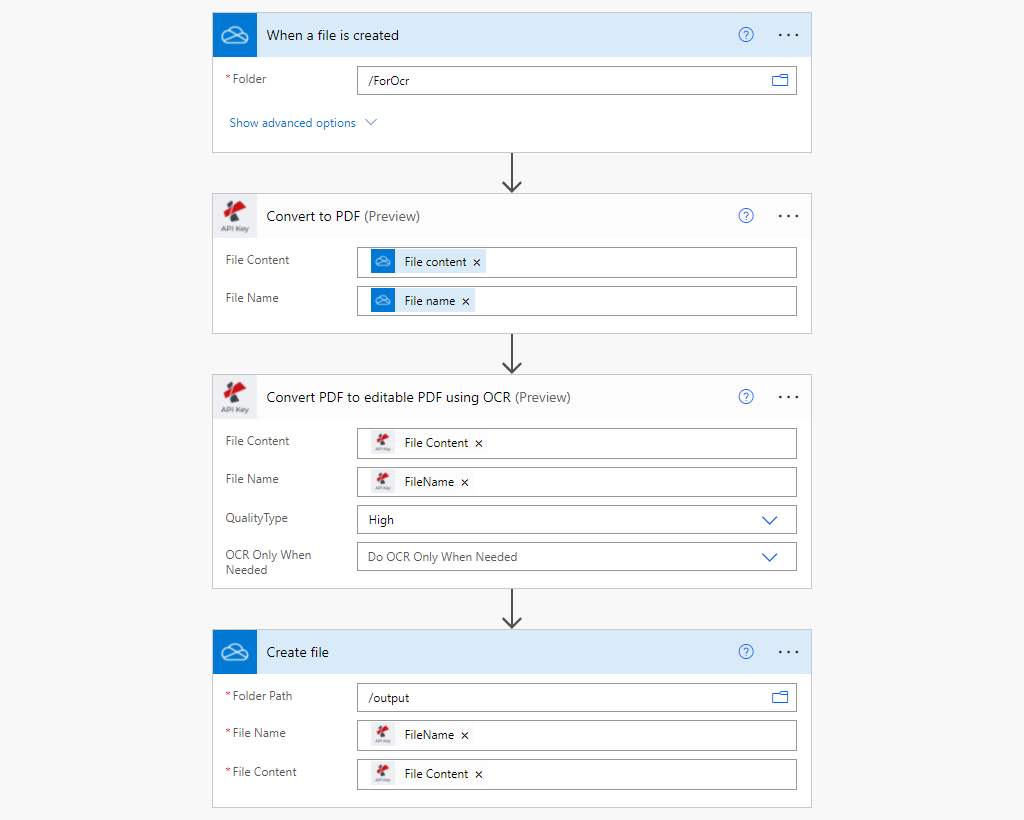
Power Automate tiene múltiples tipos de disparadores para iniciar su flujo de trabajo. En este caso de uso, activamos el flujo de trabajo cuando se crea un archivo en la ubicación de la carpeta de OneDrive.

Paso 2: Añadir Convertir a PDF para las imágenes del documento
Haga clic en “Nuevo paso” después de completar la parte del activador. Aparecerá un aviso con muchas sugerencias de aplicaciones en las que tienes que buscar PDF4me y seleccionar PDF4me Connect. De la lista de Acciones seleccione la acción Convertir a PDF.

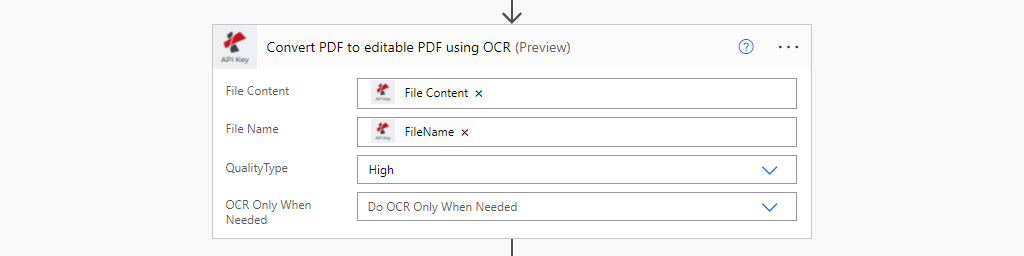
Paso 3: Elegir la acción de OCR en PDF y asignar los campos de entrada
En la lista de acciones de PDF4me, seleccione PDF OCR.
- Contenido del archivo: Contenido del archivo de entrada de la acción de origen
- Nombre del archivo: Contenido del archivo de entrada de la acción de origen
- Tipo de calidad: Elija el tipo de calidad. Borrador o Alto.
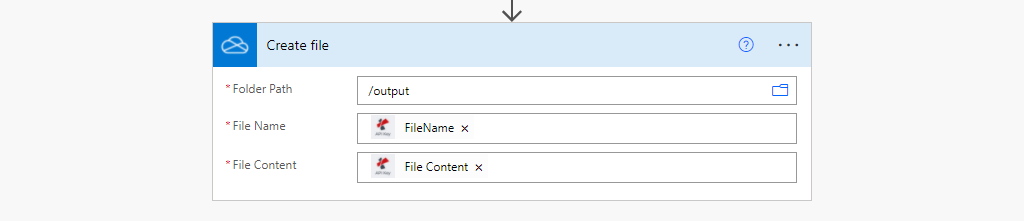
Paso 4: Guardar el archivo procesado por el OCR en la ubicación de OneDrive
Este es un paso final para guardar los archivos de salida convertidos en la ubicación de la carpeta de OneDrive.
Puedes probar la herramienta Convert to PDF y PDF OCR en línea para ver la calidad de las conversiones.
Empezar a trabajar
Para que puedas empezar rápidamente, tenemos unas cuantas plantillas listas para que empieces.
Con una de PDF4me Suscripción de desarrollador, cree flujos de trabajo de OCR de PDF y una automatización más impresionante y ahorre un tiempo valioso para centrarse en las cosas más importantes.


