
Trier et renommer automatiquement les documents PDF numérisés
La classification des documents est un grand défi depuis plusieurs décennies dans presque tous les secteurs d’activité, et elle est très importante dans divers processus commerciaux. Traditionnellement, ce processus est effectué manuellement, c’est-à-dire que les utilisateurs lisent le document et identifient le sujet pour classer les documents. Même si ce processus manuel permet de classer les documents avec plus de précision, il prend beaucoup de temps et est très coûteux.
La numérisation des processus d’entreprise a permis de réduire considérablement les efforts manuels au fil du temps, ce qui a entraîné une croissance plus rapide des économies. De nombreux outils et services d’automatisation du travail sur les documents, déjà disponibles sur le marché, permettent d’accélérer les processus d’entreprise et de les rendre facilement évolutifs. Dans ce cadre, l’organisation de grands volumes de documents qui entrent dans votre processus d’entreprise doit être plus rapide. Le processus de tri et d’organisation peut être effectué automatiquement avec des fonctions de soutien en utilisant la fonction PDF4me Workflow.
Pour vous permettre de mieux comprendre, nous avons pris un cas d’utilisation spécifique
- Trouver le numéro de facture du document en utilisant des expressions régulières et renommer le fichier avec le numéro de facture, et expliqué étape par étape en détail.
3 étapes faciles pour trier vos documents, les renommer et les enregistrer dans un espace de stockage bien trié.
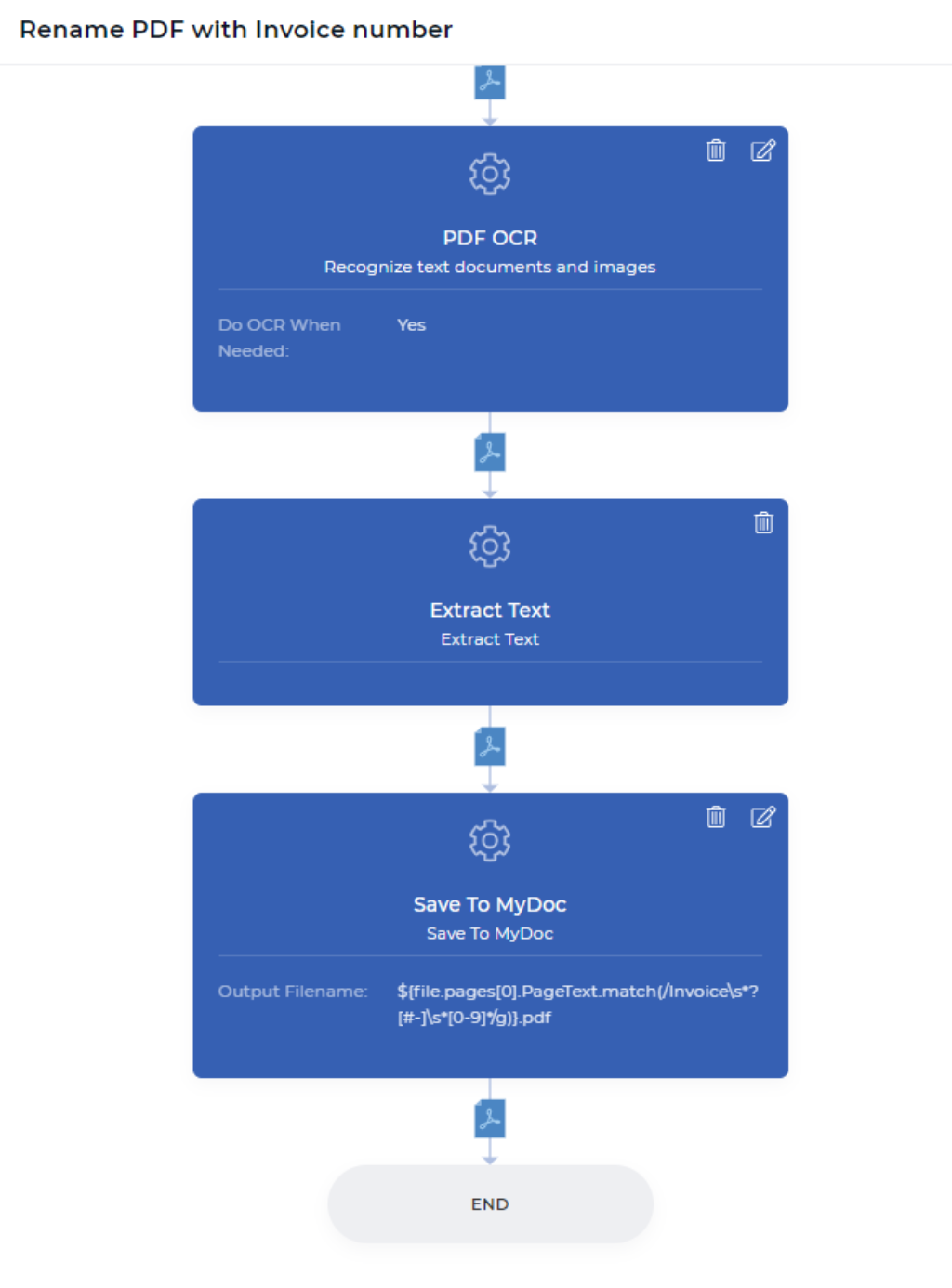
Étape 1 : Ne faire l’OCR que lorsque c’est nécessaire
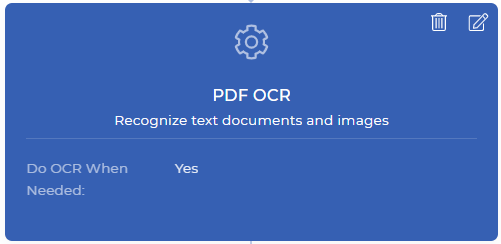
Ce serait la toute première étape de votre action de flux de travail de PDF4me. L’action PDF OCR est une fonction puissante, qui peut détecter si votre document d’entrée est un document numérisé ou un document texte, et appliquer l’OCR uniquement lorsque cela est nécessaire. Habituellement, l’OCR est un peu plus coûteux que d’autres fonctions, car il implique des ressources dédiées avec de puissants moteurs d’OCR et des composants connexes.
Dans le flux de travail d’automatisation, il peut arriver que vous ayez besoin de l’OCR lorsque le document est une image numérisée. Vous n’avez pas besoin de payer inutilement lorsque vous n’avez pas vraiment besoin d’appliquer l’OCR lorsque votre document n’a pas d’image numérisée. Il suffit d’activer l’option “Do OCR When Needed” lors de l’ajout de l’action OCR dans votre flux de travail. Cette action produit un fichier PDF textuel après la conversion ou renvoie le même fichier lorsqu’il ne nécessite pas de conversion.
Étape 2 : Extraire le texte de chaque page de votre document PDF
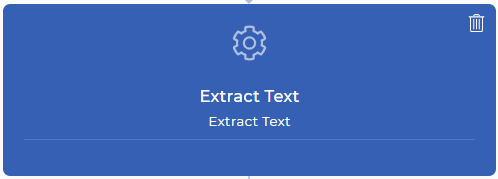
L’action de flux de travail Extraire le texte apportera tout le contenu de votre page dans le contexte de données de votre prochaine action. Cela signifie que vous pouvez jouer avec votre contenu comme vous le souhaitez - comme analyser un texte particulier, vérifier si le texte souhaité est trouvé, combiner votre texte analysé avec votre texte personnalisé, et bien plus encore avec des expressions JavaScript. Dans cet exemple, nous allons essayer de trouver le numéro de facture d’un reçu payé en ligne.
Exemple de facture PDF :

À partir de ce fichier PDF, nous voulons analyser le numéro de facture et, à l’aide de ce numéro, nous renommerons le fichier et le stockerons dans le stockage en nuage de PDF4me My Docs enfin.
Le contexte de données de sortie de cette action contiendra le texte dans le format ci-dessous.
${file.pages[0].PageText}
[0] - ceci indique le numéro de page à partir de zéro, il peut être défini à n’importe quel nombre pour obtenir le texte de la page à partir de n’importe quelle plage de pages de votre document PDF.
Ajouter une expression régulière pour trouver une correspondance à partir du contexte de données PageText comme ci-dessous.
${file.pages[0].PageText.match(/Facture\s* ?[#-]\s*[0-9]*/g)}
Il s’agit d’une simple fonction JavaScript pour appliquer une expression régulière avec les résultats de votre contexte de données. Cette expression régulière essaie de trouver le numéro de facture avec l’étiquette de la facture.
Ainsi, vous pouvez utiliser des fonctions JavaScript pour appliquer n’importe quelle fonction logique afin d’identifier votre document et prendre une décision pour le classer de manière plus précise et sans aucun effort manuel.
Étape 3 : Renommer et enregistrer le document dans Mon stockage de documents
Save To MyDoc est une action PDF4me, qui vous permet d’enregistrer votre document dans le stockage PDF4me. Si vous voulez le stocker dans votre Dropbox, FTP, ou Google Drive est également possible. Pour les besoins de la démonstration, nous utilisons le stockage My Docs pour le moment. Toutes les actions d’enregistrement ont un nom de fichier de sortie, qui est un champ non obligatoire.
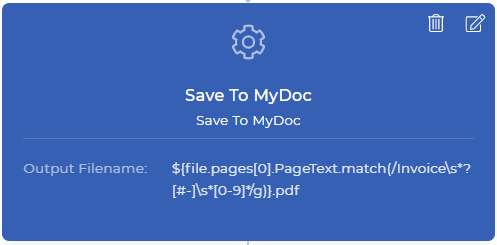
Vous pouvez définir votre nom de fichier personnalisé avec n’importe quelle combinaison dynamique comme " ${INV}-{UTCNOW()}.pdf`` - Cela produira des documents préfixés par INV- et suffixés par l’heure UTC actuelle de manière dynamique. Vous avez le contrôle sur ce que vous voulez stocker et où stocker vos documents de sortie. Dans notre cas d’utilisation de démonstration, nous devons placer le contexte de données avec l’expression régulière pour générer un nouveau nom de fichier comme ci-dessous.
${file.pages[0].PageText.match(/Facture\s* ?[#-]\s*[0-9]*/g)}.pdf
Après avoir exécuté toutes ces étapes arborescentes, votre document sera classé, renommé et stocké dans l’emplacement de stockage de fichiers de votre choix. C’est si facile pour vous maintenant ? Oui, PDF4me pense toujours du point de vue de l’utilisateur final et lui rend la vie si facile dans le monde du traitement des documents.


