

OCR avancée pour les images avec Power Automate
Nous capturons beaucoup d’images de documents ou de surfaces avec du texte pour en extraire les données ou pour les consulter ultérieurement. La conversion de documents ou d’images numérisés en fichiers PDF permettant la recherche de texte est importante pour leur traitement ultérieur. Pour rendre les PDF interrogeables, la technologie la plus utilisée est la reconnaissance optique de caractères (OCR).
PDF4me fournit une OCR PDF de haute qualité qui produit l’une des reconnaissances de texte les plus précises. Mais lorsque vous avez des centaines de documents scannés qui doivent être reconnus, la seule solution est l’automatisation. PDF4me a une solution pour cela aussi.
Combiné à Power Automate de Microsoft Power Apps, PDF4me peut automatiser les processus commerciaux impliquant des tâches documentaires banales et fastidieuses. PDF4me avec Power Automate vous connectera aux sources de données, aux applications et aux services afin de créer facilement des flux de travail robustes pour automatiser les tâches liées aux documents.
Comment utiliser l’OCR dans Power Automate ?
Voyons un exemple où nous pouvons transformer une image en PDF avec l’action PDF4me OCR dans Power Automate. Disons que nous avons des images de documents ou des images avec du texte dans OneDrive ou que nous attendons qu’elles arrivent dans un dossier spécifique. Convertissons-les en PDF et exécutons l’OCR.
Vous pouvez essayer l’outil Image to PDF et PDF OCR en ligne pour voir la qualité des conversions.
Ajouter un déclencheur pour OneDrive
Power Automate dispose de plusieurs types de déclencheurs pour démarrer votre flux de travail. Dans ce cas d’utilisation, ajoutez un déclencheur OneDrive pour lancer l’automatisation.
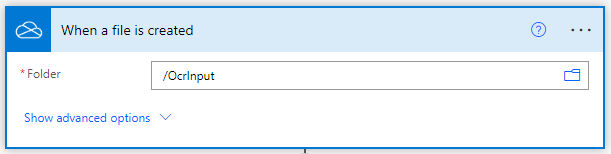
Ajouter Convert to PDF pour les images de documents
Cliquez sur “Nouvelle étape” après avoir rempli la partie “Déclencheur”. Une invite avec de nombreuses suggestions d’applications où vous devez rechercher PDF4me et sélectionner PDF4me Connect. Dans la liste des actions sélectionnez l’action Convertir en PDF.
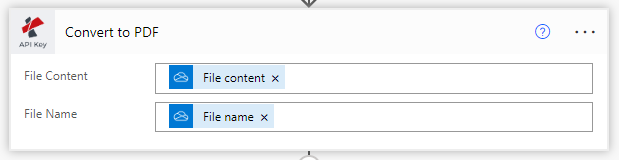
Choisissez Convertir les PDF en fichiers éditables à l’aide de l’action OCR.
Dans les actions de PDF4me, listez sélectionnez PDF OCR.
Contenu du fichier: Contenu du fichier d’entrée de l’action source
Nom du fichier: Contenu du fichier d’entrée de l’action source
Type de qualité: Choisissez le type de qualité. Draft ou High
PDF4me recommande le profil de qualité High OCR pour les images qui assure une reconnaissance précise même à partir d’images complexes.
Définissez l’option “OCR only when required” sur true, afin que l’action n’effectue pas d’OCR sur un PDF qui est déjà reconnu. Cela permet d’économiser les coûts d’appel.
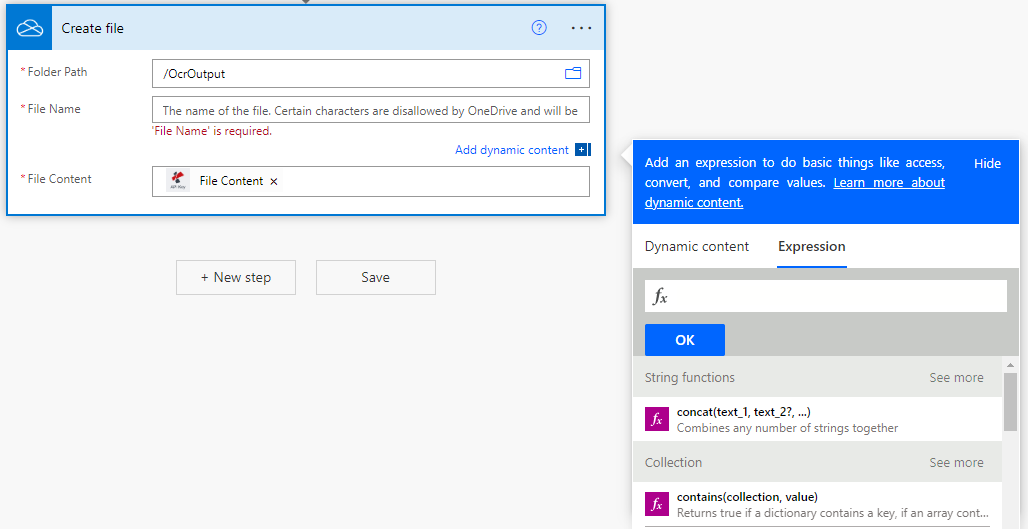
Sauvegarder les fichiers traités par l’OCR
Enfin, après l’action OCR, ajoutez une action pour enregistrer les fichiers PDF de sortie dans le stockage souhaité. Dans l’exemple, nous utilisons à nouveau une action de sauvegarde OneDrive.
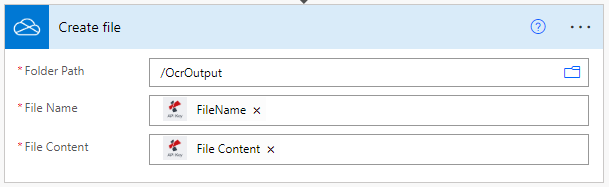
Vous pouvez également utiliser des expressions régulières (RegEx) dans le champ “Nom du fichier” pour créer des noms dynamiques afin de mieux trier les documents traités.
Modèles prêts à l’emploi pour l’OCR
Pour vous permettre de démarrer rapidement, nous vous proposons quelques modèles prêts à l’emploi.
Avec un PDF4me Abonnement développeur, créez des flux de travail PDF OCR et d’autres automatisations géniales et gagnez un temps précieux pour vous concentrer sur les choses les plus importantes.


