

OCR avançado para imagens usando Power Automate
Capturamos muitas imagens de documentos ou superfícies com texto para extrair os dados ou para referência posterior. A conversão de documentos ou imagens digitalizadas em ficheiros PDF pesquisáveis por texto é importante para o seu processamento posterior. Para tornar os PDFs pesquisáveis, a tecnologia mais utilizada é o reconhecimento óptico de caracteres - OCR.
PDF4me fornece OCR PDF de alta qualidade que produz um dos reconhecimentos de texto mais precisos. Mas quando se tem centenas de documentos digitalizados que precisam de ser reconhecidos, a única solução seria a automatização. O PDF4me também tem uma solução para isso.
Combinado com Power Automate da Microsoft Power Apps, PDF4me pode automatizar processos empresariais envolvendo trabalhos documentais que são mundanos e demorados. PDF4me com Power Automate irá conectá-lo através de fontes de dados, aplicações, e serviços para facilmente criar fluxos de trabalho robustos para automatizar trabalhos de documentos.
Como utilizar o OCR no Power Automate?
Vejamos um exemplo onde podemos transformar uma imagem em PDF com acção PDF4me OCR em Power Automate. Digamos que temos algumas imagens de documentos ou imagens com texto na OneDrive ou esperamos que cheguem a uma pasta específica. Vamos convertê-las para PDF e realizar o OCR.
Pode experimentar a ferramenta Image to PDF e PDF OCR online para ver a qualidade das conversões.
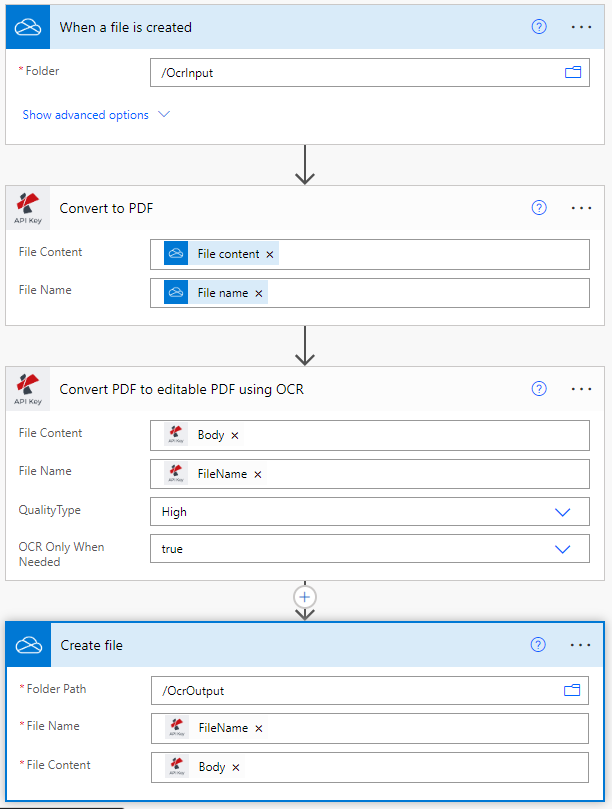
Adicionar um gatilho para a OneDrive
Power Automate tem múltiplos tipos de gatilhos para iniciar o seu fluxo de trabalho. Neste caso de utilização, adicione um gatilho OneDrive para iniciar a automatização.
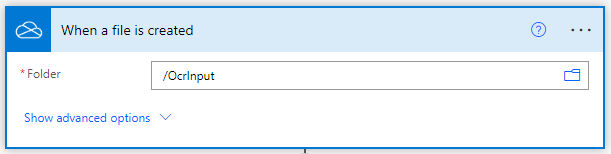
Adicionar Converter em PDF para imagens de documentos
Clique em ‘Novo Passo’ depois de completar a parte do Gatilho. Um prompt com muitas sugestões de aplicação onde tem de procurar PDF4me e seleccionar PDF4me Connect. A partir da lista de acções seleccionar a acção Converter para PDF.
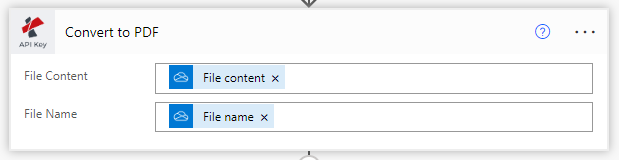
Escolha Converter PDF para editável usando acção de OCR
Das acções PDF4me, lista seleccionar PDF OCR.
Conteúdo do ficheiro: Introduza o conteúdo do ficheiro a partir da acção da fonte
Nome do ficheiro: Introduza o conteúdo do ficheiro a partir da acção da fonte
Qualidade Tipo: Escolher o tipo de qualidade. Aprojeto ou Alto
PDF4me recomenda OCR de alto perfil de qualidade para imagens que assegura um reconhecimento preciso mesmo a partir de imagens complexas.
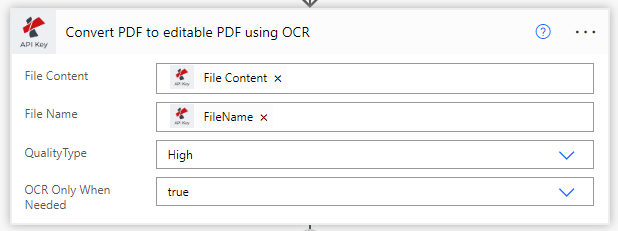
Definir o ‘OCR apenas quando necessário’ para verdadeiro, para que a acção não execute OCR num PDF que já seja reconhecido. Desta forma, poupa custos de chamada.
Guardar ficheiros processados OCR
Finalmente, após a acção de OCR adicionar uma acção para armazenar os ficheiros PDF de saída ao armazenamento desejado. No exemplo, utilizamos novamente uma acção de salvaguarda OneDrive.
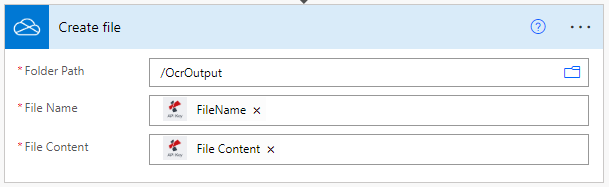
Pode utilizar também utilizar expressões regulares(RegEx) no campo ‘Nome de ficheiro’ para criar nomes dinâmicos para melhor ordenação dos documentos processados.
Modelos prontos a usar para OCR
Para que possa começar rapidamente, temos alguns modelos prontos para começar.
Com um PDF4me Assinatura do Desenvolvedor, criar fluxos de trabalho PDF OCR e uma automatização mais espectacular e poupar tempo valioso para se concentrar nas coisas mais importantes.


