

OCR avanzado para imágenes con Power Automate
Capturamos muchas imágenes de documentos o superficies con texto para extraer los datos o para su posterior consulta. Convertir los documentos o imágenes escaneados en archivos PDF con capacidad de búsqueda de texto es importante para su posterior procesamiento. Para hacer que los PDF se puedan buscar, la tecnología más utilizada es el reconocimiento óptico de caracteres (OCR).
PDF4me proporciona OCR de alta calidad para PDF que produce uno de los reconocimientos de texto más precisos. Pero cuando usted tiene cientos de documentos escaneados que necesitan ser reconocidos la única solución sería la automatización. PDF4me tiene una solución para eso también.
En combinación con Power Automate de Power Apps de Microsoft, PDF4me puede automatizar los procesos empresariales que implican trabajos documentales que son mundanos y que consumen mucho tiempo. PDF4me con Power Automate le conectará a través de fuentes de datos, aplicaciones y servicios para crear fácilmente flujos de trabajo robustos para automatizar trabajos de documentos.
¿Cómo utilizar el OCR en Power Automate?
Veamos un ejemplo en el que podemos transformar una imagen a PDF con la acción OCR de PDF4me en Power Automate. Digamos que tenemos algunas imágenes de documentos o imágenes con texto en OneDrive o esperamos que lleguen a una carpeta específica. Convirtámoslas en PDF y realicemos el OCR.
Puede probar la herramienta Image to PDF y PDF OCR en línea para ver la calidad de las conversiones.
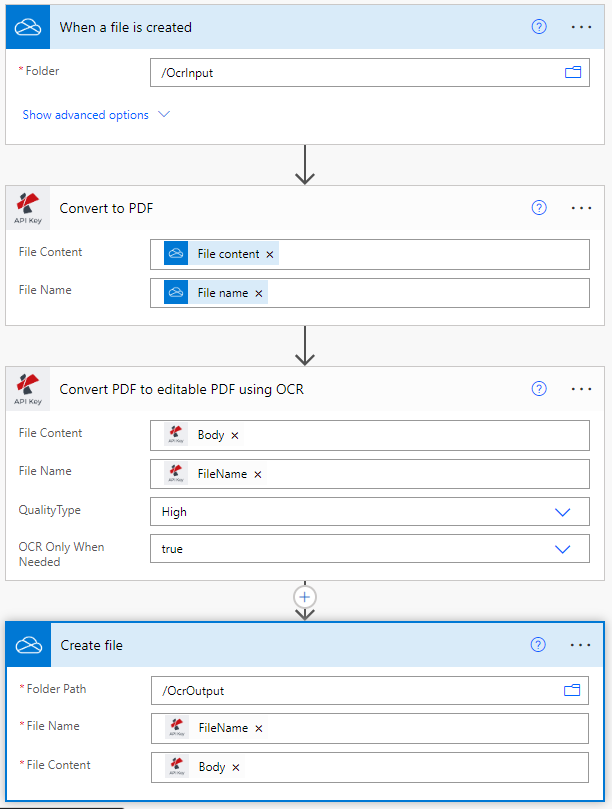
Añadir un activador para OneDrive
Power Automate tiene varios tipos de activadores para iniciar su flujo de trabajo. En este caso de uso, añada un activador de OneDrive para iniciar la automatización.
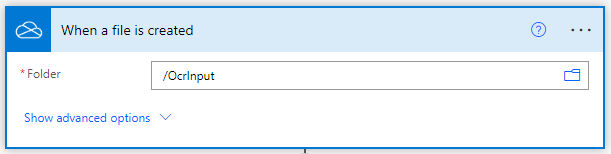
Añadir Convertir a PDF para imágenes de documentos
Haga clic en “Nuevo paso” después de completar la parte del activador. Aparecerá un aviso con muchas sugerencias de aplicaciones en las que tienes que buscar PDF4me y seleccionar PDF4me Connect. De la lista de Acciones seleccione la acción Convertir a PDF.
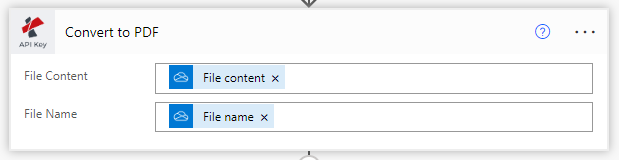
Elija Convertir PDF en editable mediante la acción OCR
Desde las acciones de PDF4me, lista seleccionar PDF OCR.
Contenido del archivo: Contenido del archivo de entrada de la acción de origen
Nombre del archivo: Contenido del archivo de entrada de la acción de origen
Tipo de calidad: Elija el tipo de calidad. Borrador o Alta.
PDF4me recomienda un perfil de OCR de alta calidad para imágenes que garantiza un reconocimiento preciso incluso de imágenes complejas.
Establezca la opción “OCR sólo cuando sea necesario” en true, para que la acción no realice el OCR en un PDF que ya esté reconocido. De este modo, se ahorran los costes de las llamadas.
Guardar los archivos procesados por el OCR
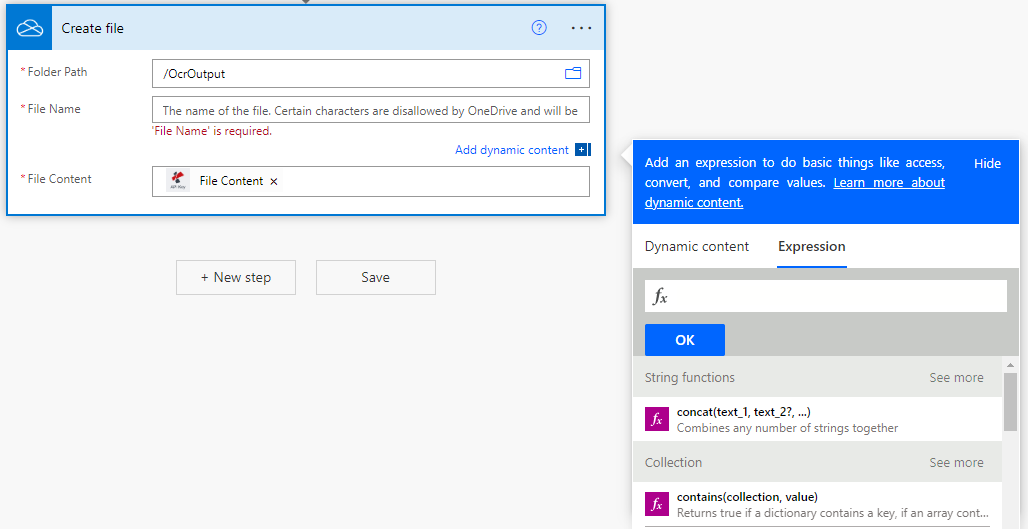
Por último, después de la acción de OCR añada una acción para almacenar los archivos PDF de salida en el almacenamiento deseado. En el ejemplo volvemos a utilizar una acción de guardar en OneDrive.
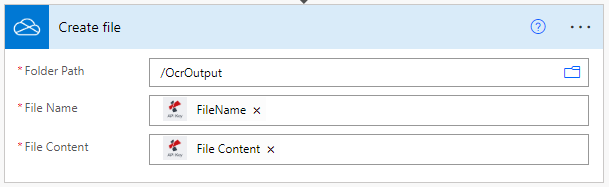
También puede utilizar expresiones regulares (RegEx) en el campo ‘Nombre de archivo’ para crear nombres dinámicos para una mejor clasificación de los documentos procesados.
Plantillas listas para el OCR
Para que puedas empezar rápidamente, tenemos unas cuantas plantillas listas para que empieces.
Con una PDF4me Suscripción para desarrolladores, cree flujos de trabajo de OCR de PDF y una automatización más impresionante y ahorre un tiempo valioso para centrarse en las cosas más importantes.


