
Ordenar y renombrar automáticamente los documentos PDF escaneados
La clasificación de documentos es un gran reto desde hace muchas décadas en casi todas las industrias, y tiene una necesidad muy importante en varios procesos empresariales. Tradicionalmente, este proceso se realiza de forma manual, como los usuarios leen el documento e identifican el tema para clasificar los documentos. Aunque el proceso manual ayuda a clasificar con mayor precisión, requiere mucho tiempo y es muy caro.
La digitalización de los procesos empresariales ha reducido considerablemente los esfuerzos manuales a lo largo del tiempo, lo que ha dado lugar a un crecimiento más rápido de las economías. Hay muchas herramientas y servicios de automatización del trabajo documental que ya están disponibles en el mercado y que pueden facilitar que los procesos empresariales sean más rápidos y fácilmente escalables. Como parte de esto, la organización de grandes volúmenes de documentos que entran en su proceso de negocio debe ser más rápida. El proceso de clasificación y organización puede hacerse automáticamente con funciones de apoyo utilizando la función PDF4me Workflow.
Para su mejor comprensión, hemos tomado un caso de uso específico
- Encuentre el número de factura del documento utilizando expresiones regulares y cambie el nombre del archivo con el número de factura, y se explica paso a paso en detalle.
3 sencillos pasos para ordenar tus documentos, renombrarlos y guardarlos bien ordenados.
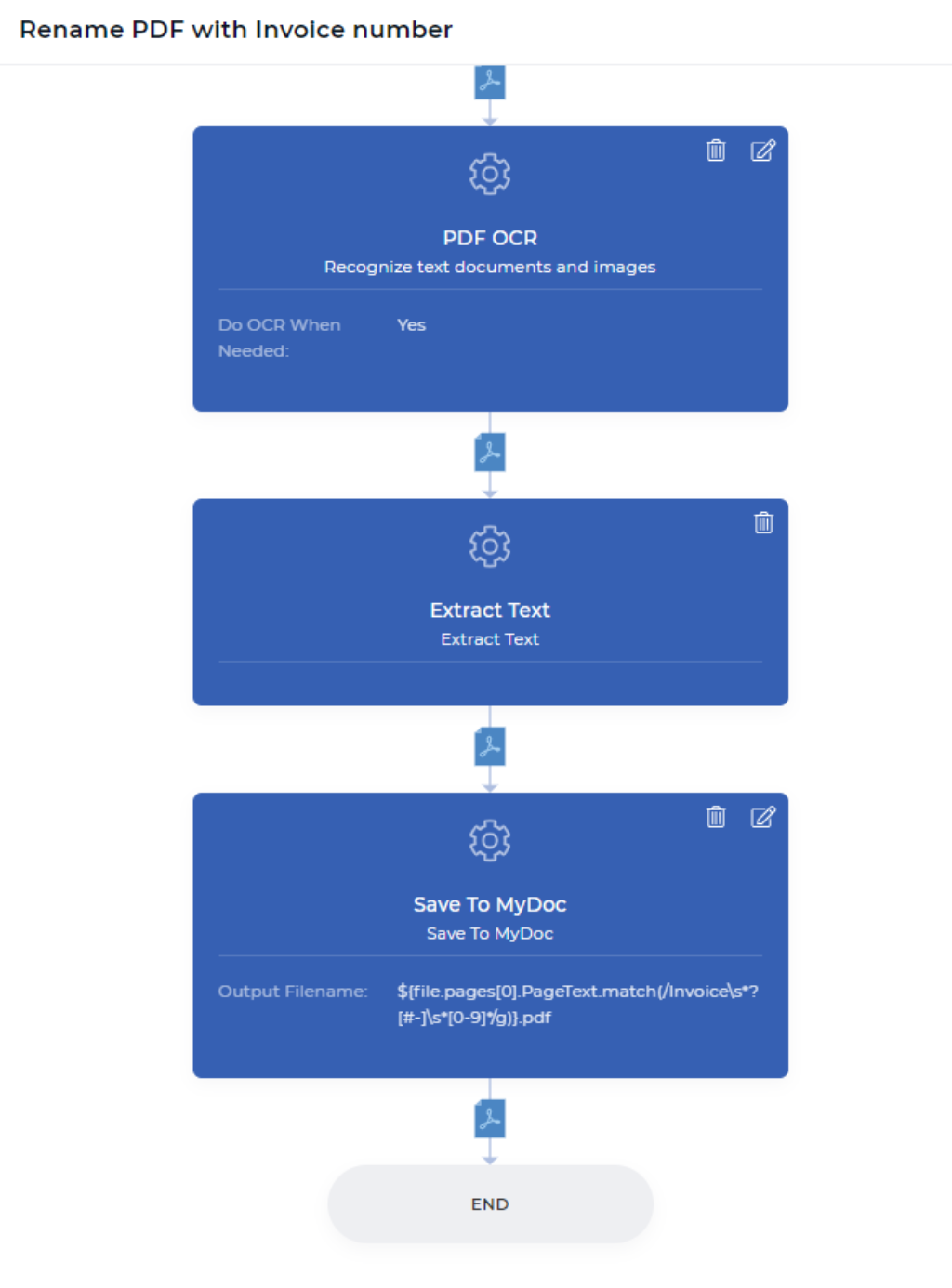
Paso 1: Realice el OCR sólo cuando sea necesario
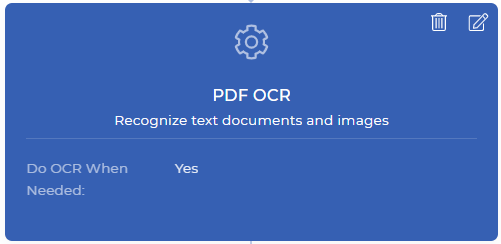
Este sería el primer paso de su acción de flujo de trabajo de PDF4me. La acción de OCR en PDF es una potente función que puede detectar si su documento de entrada es un documento escaneado o un documento basado en texto, y aplicar el OCR sólo cuando sea necesario. Por lo general, el OCR es un poco más costoso que otras funciones, ya que implica recursos dedicados con potentes motores de OCR y componentes relacionados.
En el flujo de trabajo de automatización, puede haber situaciones en las que se necesite OCR a veces cuando el documento es una imagen escaneada. No necesita pagar innecesariamente cuando no necesita realmente aplicar el OCR cuando su documento no tiene una imagen escaneada. Sólo tiene que activar la opción “Hacer OCR cuando sea necesario” al añadir la acción de OCR en su flujo de trabajo. Esta acción produce un archivo PDF basado en texto después de la conversión o devuelve el mismo archivo cuando no requiere conversión.
Paso 2: Extraer el texto de cada página de su documento PDF
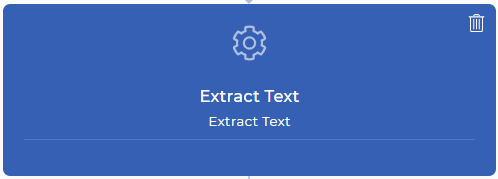
La acción de flujo de trabajo Extraer Texto llevará todo el contenido de su página a su siguiente contexto de datos de acción. Esto significa que puede jugar con su contenido como quiera - como analizar un texto en particular, comprobar si el texto deseado se encuentra, combinar su texto analizado con su texto personalizado, y muchos más con expresiones de JavaScript. En este ejemplo, trataremos de encontrar el número de factura de un recibo pagado en línea.
Ejemplo de factura en PDF:

De este archivo PDF queremos analizar el número de la factura y usando este número renombraremos el archivo y lo almacenaremos en el almacenamiento en la nube de PDF4me My Docs finalmente.
El contexto de datos de salida de esta acción contendrá el texto en el formato siguiente.
${file.pages[0].PageText}
```[0]`` - indica el número de página empezando por cero, se puede establecer en cualquier número para obtener el texto de la página de cualquier rango de páginas de su documento PDF.
Añade una expresión regular para encontrar una coincidencia en el contexto de datos de PageText como se indica a continuación.
```${file.pages[0].PageText.match(/Factura*?[#-]\s*[0-9]*/g)}`````
Esta es una simple función de JavaScript para aplicar una expresión regular junto con los resultados de su contexto de datos. Este regex tratando de encontrar el número de factura junto con la etiqueta de la factura.
Así, puede hacer uso de las funciones de JavaScript para aplicar cualquier función lógica para identificar su documento y tomar una decisión para clasificarlo con mayor precisión y sin ningún esfuerzo manual.
Paso 3: Cambiar el nombre y guardarlo en Mi almacén de documentos
Guardar en MiDoc es una acción de PDF4me, que le permite guardar su documento en el almacenamiento de PDF4me. Si desea almacenar esto en su Dropbox, FTP, o Google Drive también es posible. Para el propósito de la demostración, usamos el almacenamiento de My Docs por ahora. Todas las acciones de guardar en tienen un nombre de archivo de salida, que es un campo no obligatorio.
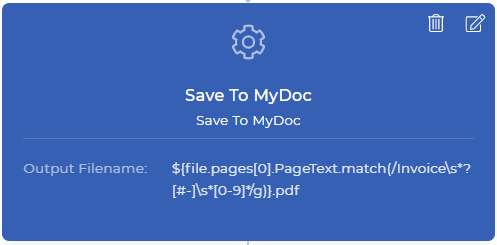
Puede establecer su nombre de archivo personalizado con cualquier combinación dinámica como ${INV}-{UTCNOW()}.pdf - Esto producirá documentos con el prefijo INV- y el sufijo de la hora UTC actual de forma dinámica. Usted tiene el control sobre qué almacenar y dónde almacenar sus documentos de salida. En nuestro caso de uso de demostración, necesitamos colocar el contexto de datos junto con la expresión regular para generar un nuevo nombre de archivo como el que se muestra a continuación.
${file.pages[0].PageText.match(/Factura*?[#-]\s*[0-9]*/g)}.pdf
Después de ejecutar todos estos pasos del árbol, su documento será clasificado, renombrado y almacenado con la ubicación de almacenamiento de archivos que desee. ¿Qué tan fácil es esto para usted ahora? Sí, PDF4me siempre piensa desde la perspectiva del usuario final y le hace la vida muy fácil en el mundo del procesamiento de documentos.


