
Ordinamento e rinominazione automatica dei documenti PDF scansionati
La classificazione dei documenti è una grande sfida da molti decenni in quasi tutti i settori e ha una necessità molto importante in vari processi aziendali. Tradizionalmente, questo processo viene eseguito manualmente: gli utenti leggono i documenti e ne identificano l’oggetto per classificarli. Anche se il processo manuale aiuta a classificare in modo più preciso, richiede molto tempo ed è molto costoso.
La digitalizzazione dei processi aziendali ha ridotto nel tempo gli sforzi manuali e ha portato a una crescita più rapida delle economie. Esistono molti strumenti e servizi di automazione del lavoro documentale già disponibili sul mercato, che possono facilitare i processi aziendali e renderli più veloci e facilmente scalabili. In questo contesto, l’organizzazione di grandi volumi di documenti che entrano nel processo aziendale deve essere più veloce. Il processo di ordinamento e organizzazione può essere eseguito automaticamente con funzioni di supporto utilizzando la funzione PDF4me Workflow.
Per una migliore comprensione, abbiamo preso in esame un caso d’uso specifico
- Trovare il numero di fattura dal documento utilizzando le espressioni regolari e rinominare il file con il numero di fattura, e spiegato passo per passo in dettaglio.
3 semplici passaggi per ordinare i documenti, rinominarli e salvarli in un archivio ben ordinato.
Passo 1: eseguire l’OCR solo quando necessario
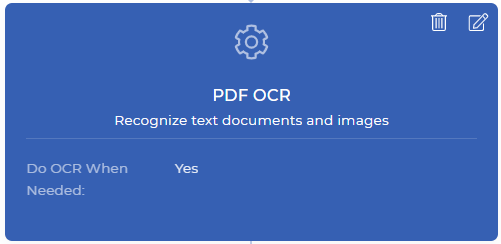
Questa è la prima fase del flusso di lavoro di PDF4me. L’azione PDF OCR è una funzione potente, in grado di rilevare se il documento in ingresso è un documento scansionato o un documento basato su testo, e di applicare l’OCR solo quando necessario. Di solito, l’OCR è un po’ più costoso di altre funzioni, poiché richiede risorse dedicate con potenti motori OCR e componenti correlati.
Nel flusso di lavoro di automazione, potrebbero verificarsi situazioni in cui è necessario applicare l’OCR quando il documento è un’immagine scansionata. Non è necessario pagare inutilmente quando non è necessario applicare l’OCR quando il documento non ha un’immagine scansionata. È sufficiente attivare l’opzione “Esegui OCR quando necessario” quando si aggiunge l’azione OCR al flusso di lavoro. Questa azione produce un file PDF basato sul testo dopo la conversione o restituisce lo stesso file quando non è necessaria la conversione.
Passo 2: Estrarre il testo da ogni pagina del documento PDF
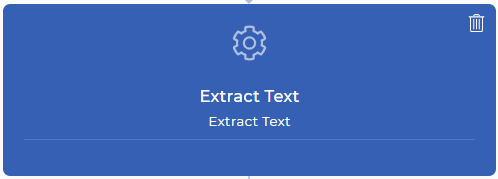
L’azione del flusso di lavoro Estrai testo porterà tutto il contenuto della pagina nel contesto dei dati dell’azione successiva. Ciò significa che si può giocare con il contenuto come si vuole, ad esempio analizzando un testo particolare, controllando se il testo desiderato è stato trovato, combinando il testo analizzato con quello personalizzato e molto altro ancora con le espressioni JavaScript. In questo esempio, cercheremo di trovare il numero di fattura da una ricevuta pagata online.
Esempio di fattura PDF:

Da questo file PDF vogliamo analizzare il numero della fattura e, utilizzando questo numero, rinominare il file e archiviarlo nel cloud storage My Docs di PDF4me.
Il contesto dei dati in uscita da questa azione conterrà il testo nel formato seguente.
``${file.pages[0].PageText}```
[0] - indica il numero di pagina a partire da zero; può essere impostato su qualsiasi numero per ottenere il testo della pagina da qualsiasi intervallo di pagine del documento PDF.
Aggiungere un’espressione regolare per trovare una corrispondenza dal contesto dei dati di PageText, come indicato di seguito.
``${file.pages[0].PageText.match(/fattura*?[#-]\s*[0-9]*/g)}```
Si tratta di una semplice funzione JavaScript per applicare un’espressione regolare ai risultati del contesto dei dati. Questa regex cerca di trovare il numero di fattura insieme all’etichetta Fattura.
In questo modo, è possibile utilizzare le funzioni JavaScript per applicare qualsiasi funzione logica per identificare il documento e prendere una decisione per classificarlo in modo più accurato e senza alcuno sforzo manuale.
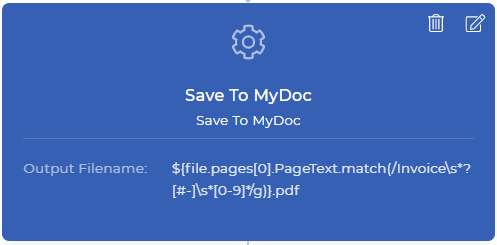
Fase 3: Rinominare e salvare in My Document Storage (Archiviazione documenti)
Save To MyDoc è un’azione di PDF4me che consente di salvare il documento nell’archivio di PDF4me. È anche possibile salvare il documento in Dropbox, FTP o Google Drive. A scopo dimostrativo, per ora utilizziamo l’archivio My Docs. Tutte le azioni di salvataggio in hanno il nome del file di output, che è un campo non obbligatorio.
È possibile impostare il nome del file personalizzato con qualsiasi combinazione dinamica come ```${INV}-{UTCNOW()}.pdf`` - Questo produrrà documenti con il prefisso INV- e il suffisso dell’ora UTC corrente in modo dinamico. Si ha il controllo su come e dove memorizzare i documenti di output. Nel nostro caso d’uso dimostrativo, dobbiamo inserire il contesto dei dati insieme all’espressione regolare per generare un nuovo nome di file, come di seguito.
```${file.pages[0].PageText.match(/Fattura*?[#-]\s*[0-9]*/g)}.pdf ````
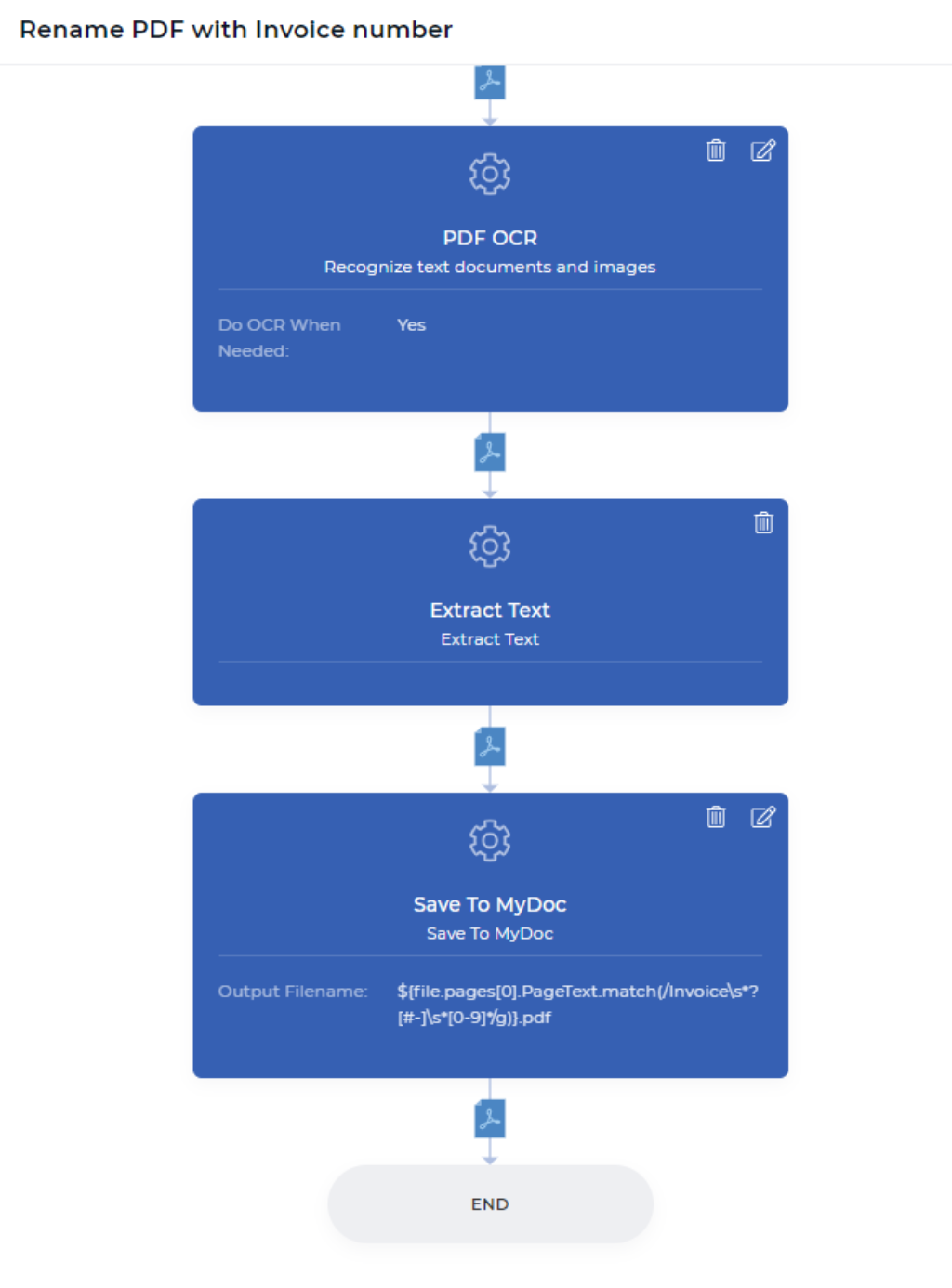
Dopo aver eseguito tutti questi passaggi ad albero, il documento verrà classificato, rinominato e memorizzato nella posizione di archiviazione desiderata. Quanto è facile per voi? Sì, PDF4me pensa sempre dal punto di vista dell’utente finale e gli semplifica la vita nel mondo dell’elaborazione dei documenti.


