

OCR avanzato per le immagini con Power Automate
Acquisiamo molte immagini di documenti o superfici con testo per estrarre i dati o per una successiva consultazione. La conversione dei documenti o delle immagini scansionate in file PDF ricercabili è importante per la loro successiva elaborazione. Per rendere i PDF ricercabili, la tecnologia più utilizzata è il riconoscimento ottico dei caratteri (OCR).
PDF4me fornisce un OCR PDF di alta qualità che produce uno dei più accurati riconoscimenti di testo. Ma quando si hanno centinaia di documenti scansionati che devono essere riconosciuti, l’unica soluzione è l’automazione. PDF4me ha una soluzione anche per questo.
In combinazione con Power Automate di Power Apps di Microsoft, PDF4me è in grado di automatizzare i processi aziendali che coinvolgono lavori documentali banali e dispendiosi in termini di tempo. PDF4me con Power Automate vi connetterà tra le fonti di dati, le app e i servizi per creare facilmente solidi flussi di lavoro per automatizzare i processi documentali.
Come utilizzare l’OCR in Power Automate?
Vediamo un esempio in cui possiamo trasformare un’immagine in PDF con l’azione PDF4me OCR in Power Automate. Supponiamo di avere alcune immagini di documenti o immagini con testo in OneDrive o che ci aspettiamo che arrivino in una cartella specifica. Convertiamole in PDF ed eseguiamo l’OCR.
È possibile provare online lo strumento Image to PDF e PDF OCR per verificare la qualità delle conversioni.
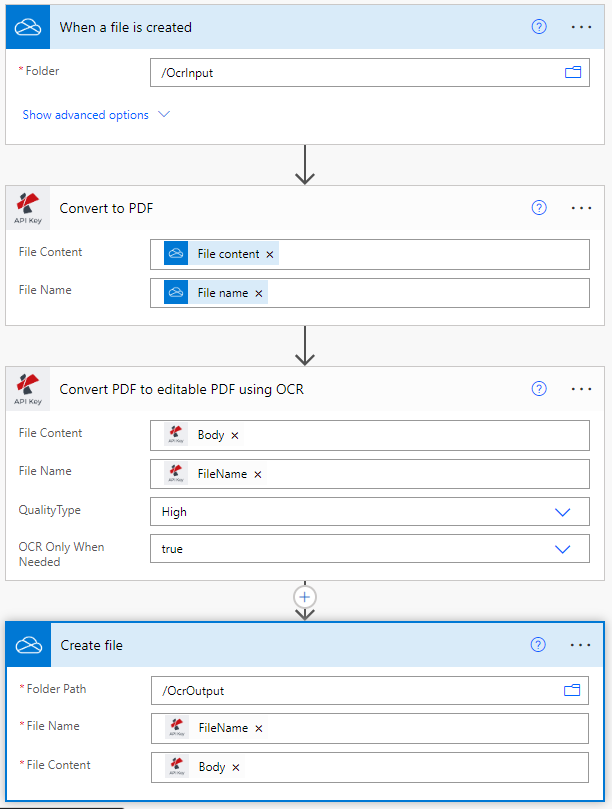
Aggiungere un trigger per OneDrive
Power Automate offre diversi tipi di trigger per avviare il flusso di lavoro. In questo caso d’uso, aggiungere un trigger OneDrive per avviare l’automazione.
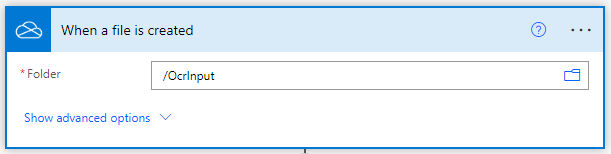
Aggiungi Converti in PDF per le immagini dei documenti
Fare clic su “Nuovo passo” dopo aver completato la parte relativa al trigger. Verrà visualizzato un prompt con molti suggerimenti di app in cui si deve cercare PDF4me e selezionare PDF4me Connect. Dall’elenco delle azioni selezionare l’azione Converti in PDF.
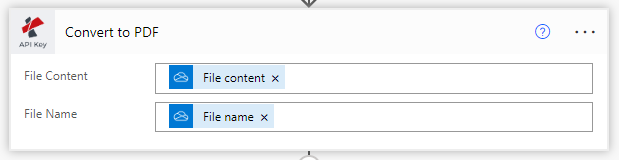
Scegliere Convertire PDF in modificabile utilizzando l’azione OCR.
Dalle azioni di PDF4me, elencare seleziona PDF OCR.
Contenuto del file: Contenuto del file in ingresso dall’azione sorgente
Nome del file: Contenuto del file di input dell’azione sorgente
Tipo di qualità: Scegliere il tipo di qualità. Stampa o Alta.
PDF4me raccomanda un profilo OCR di qualità elevata per le immagini, che garantisce un riconoscimento accurato anche di immagini complesse.
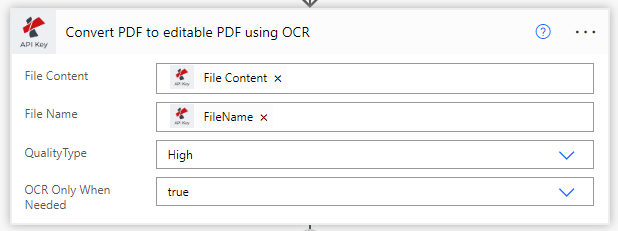
Impostare l’opzione ‘OCR solo se richiesto’ su vero, in modo che l’azione non esegua l’OCR su un PDF già riconosciuto. In questo modo, si risparmiano i costi di chiamata.
Salvare i file elaborati dall’OCR
Infine, dopo l’azione OCR, aggiungete un’azione per salvare i file PDF di output nell’archivio desiderato. Nell’esempio utilizziamo nuovamente un’azione di salvataggio su OneDrive.
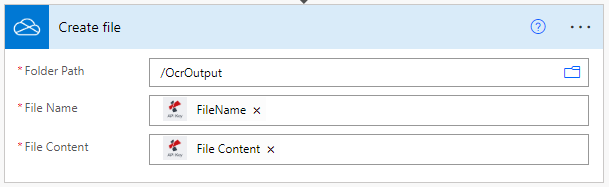
È inoltre possibile usare le espressioni regolari (RegEx) nel campo ‘Nome file’ per creare nomi dinamici per un migliore ordinamento dei documenti elaborati.
Modelli pronti all’uso per l’OCR
Per iniziare rapidamente, abbiamo preparato per voi alcuni modelli.
Con PDF4me Developer Subscription, create flussi di lavoro OCR PDF e altre fantastiche automazioni e risparmiate tempo prezioso per concentrarvi sulle cose più importanti.


