

PDF4me İş Akışlarını kullanarak metni PDF OCR ile tanıyın
Taranan belgeleri veya görüntüleri metin aranabilir PDF dosyaları olarak dönüştürmek, bu belgelerin daha fazla işlenmesi için önemlidir. PDF’leri aranabilir hale getirmek için kullanılan teknoloji optik karakter tanımadır - OCR. İşletmeler ve işletmeler için işlenmesi gereken çok sayıda belge olabilir. Bu, PDF OCR’nin otomasyonunu gerektirir.
PDF4me, en doğru metin tanıma yöntemlerinden birini üreten yüksek kaliteli PDF OCR sağlar. Ancak, tanınması gereken yüzlerce taranmış belgeniz olduğunda, tek çözüm otomasyon olacaktır. PDF4me Workflows, bu otomasyonu yürütmek için mükemmel bir eyleme sahiptir - PDF OCR.
İş Akışlarını kullanarak PDF OCR nasıl otomatikleştirilir
Taranan belgelerden veya metin içeren görüntülerden aranabilir PDF dosyaları oluşturun. Eylem, çıktı PDF’sinden metin aramanızı veya kopyalamanızı sağlar.
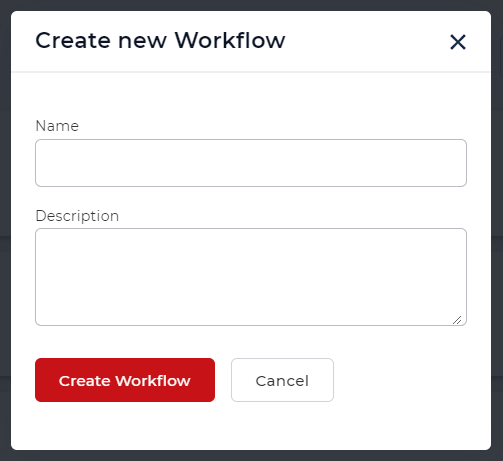
PDF OCR eylemiyle örnek bir iş akışına bakalım. İş Akışları Panosu’dan İş Akışı Oluştur’u seçerek başlayın.
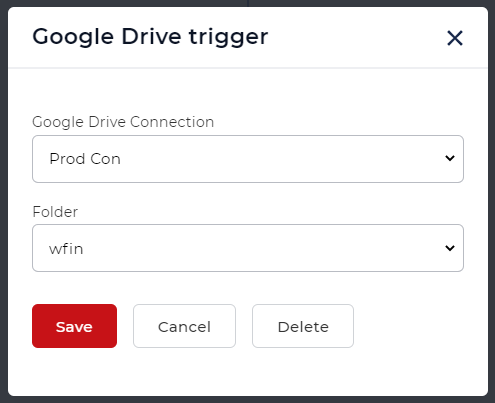
İş Akışı için bir tetikleyici ekleyin
İş Akışı otomasyonunu başlatmak için bir tetikleyici oluşturun ve yapılandırın. Tetikleyicide yapılandırılan klasöre yeni bir dosya gelir gelmez otomasyon başlatılır.
Örnek için Google Drive tetikleyicisini kullanalım.
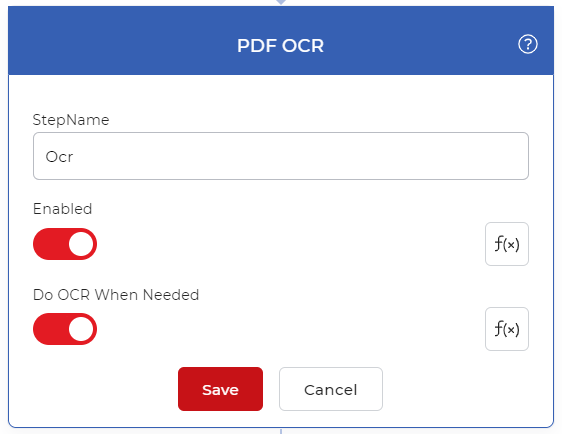
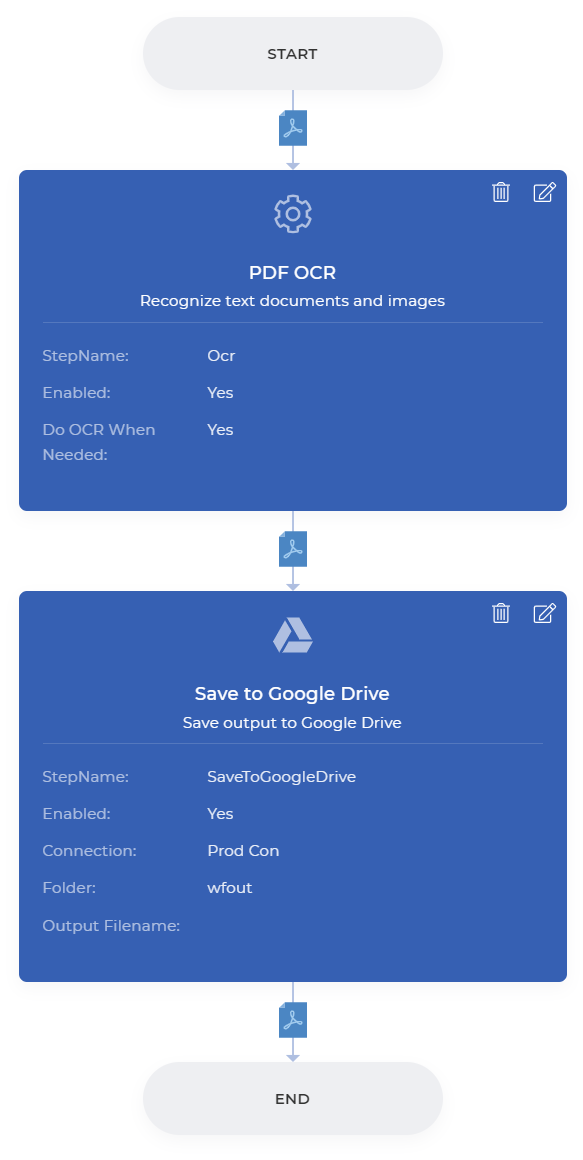
PDF OCR eylemini ekleyin
Gerektiğinde OCR’nin yalnızca gerektiğinde kullanıldığından emin olmak için ODF OCR eylemini ekleyin ve Gerektiğinde OCR Yap’ı etkinleştirin.
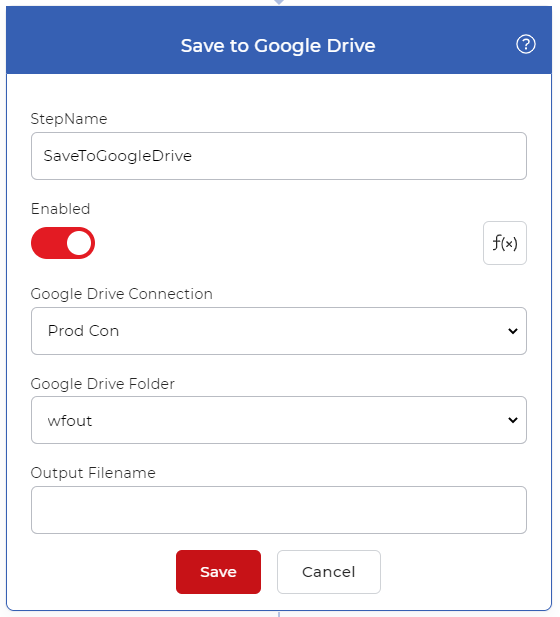
Depolama Alanına Kaydet Ekle
Çıktı dosyalarını kaydetmek için eylemi ekleyin. Örnek için Google Drive’a Kaydet’i seçebiliriz. İşlenen dosyalarınızın kaydedilmesini istediğiniz klasörü yapılandırın.
Yapılandırmalar tamamlandıktan sonra, İş Akışını Yayınlamak için Kaydet yapabilirsiniz. Örnek bir İş Akışı aşağıdaki gibi görünecektir.
İş Akışlarına erişmek için bir PDF4me Aboneliği gerekir. Hatta bir Daypass alabilir ve Belge işlerinizi otomatikleştirmeye nasıl yardımcı olabileceğini görmek için İş Akışlarını deneyebilirsiniz.


