

Scanner et diviser les PDF en fonction du texte spécifique qu'ils contiennent.
De nos jours, nous automatisons un grand nombre de processus documentaires. Vous voulez reconnaître un texte spécifique dans un PDF ? Vous voulez utiliser ce texte pour fractionner le fichier aux pages contenant le texte spécifique ? Voulez-vous renommer les fichiers fractionnés en utilisant le texte utilisé pour le fractionnement ? Eh bien, nous avons la solution parfaite pour vous.
L’action PDF4me Workflows Split By Text répond à toutes ces logiques de documents. Les flux de travail se concentrent uniquement sur la fourniture de la meilleure solution d’automatisation pour vos processus documentaires. L’action peut également stocker le texte dans le presse-papiers pour renommer les fichiers avec le texte si nécessaire tout en l’enregistrant dans le stockage. Voyons maintenant, à l’aide d’un exemple de flux de travail, comment nous pouvons configurer cette action.
Comment numériser et diviser un PDF par un texte spécifique ?
Dans l’exemple suivant, nous allons créer un flux de travail pour diviser un fichier PDF en utilisant le texte spécifique qu’il contient et utiliser le texte pour renommer les fichiers divisés.
Commencez par lancer le PDF4me Dashboard.
- Sélectionnez le bouton Créer un flux de travail.
Ajoutez un déclencheur pour lancer votre flux de travail
Ajoutez un déclencheur pour lancer votre automatisation.
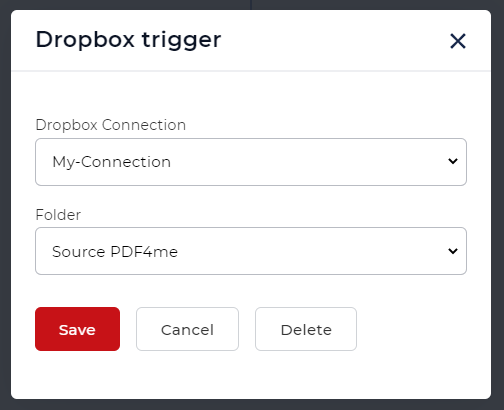
- Actuellement, les workflows fournissent 2 triggers - Dropbox et Google Drive. Par exemple, créons un déclencheur Dropbox.
Configurez la connexion et choisissez le dossier où les fichiers d’entrée sont attendus.
Pour tester le flux exact, vous pouvez utiliser cet exemple PDF - Télécharger le fichier d’exemple
Ajouter l’action Split By Text
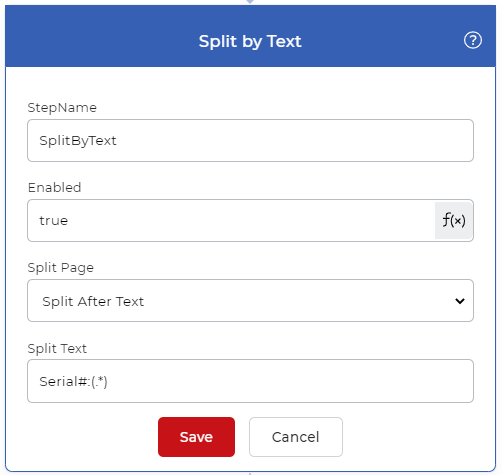
Ajoutez et configurez une action Split By Text pour séparer les pages du fichier en utilisant le texte requis. Ici, nous utilisons une expression régulière pour détecter le texte unique.
Serial# :(.*)
La regex trouvera les valeurs de texte commençant par ‘Serial#:’ et les séparera en fonction de la condition.
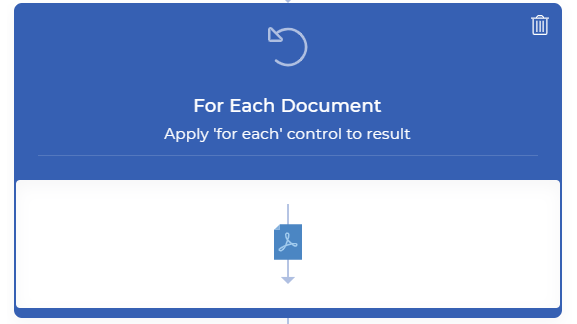
Ajouter un contrôle pour chaque Documet
Étant donné que la fonction Split By Text génère plusieurs documents, un contrôle For Each Document est nécessaire pour traiter les fichiers de sortie un par un. Le reste des actions doit être inclus dans ce contrôle.
Ajout d’une action de sauvegarde
Les fichiers de sortie devaient être sauvegardés sur un stockage en nuage. Dans notre cas d’utilisation, nous allons configurer une action Save to Dropbox. Dans l’image ci-dessus, vous pouvez voir une expression pour obtenir un texte à partir de l’action ‘Split By Text’. Vous pouvez utiliser l’expression régulière ci-dessous dans le paramètre Nom du fichier de sortie pour renommer les fichiers.
${file.pages[0].PageText}.pdf
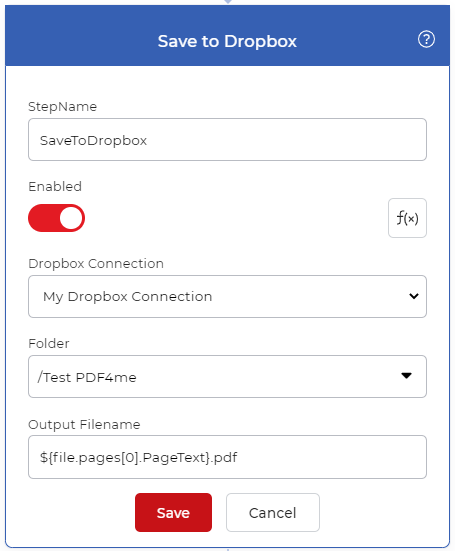
L’expression transmettra le texte de l’action Split By PDF au paramètre output filename afin que les fichiers soient renommés en fonction du texte lu.
Pour avoir accès à Workflows, il vous faut un Abonnement PDF4me. Vous pouvez même obtenir un Daypass et essayer Workflows pour voir comment il peut vous aider à automatiser vos tâches documentaires.


