

Extraire du texte d'un PDF et le réutiliser ultérieurement à l'aide de workflows
Les documents numériques remplacent très rapidement les documents papier traditionnels. De nos jours, nous en recevons beaucoup sous forme de fichiers PDF. Les documents PDF tels que les contrats, les documents juridiques ou les livres numériques peuvent contenir des centaines ou des milliers de pages. Nous automatisons un grand nombre de ces documents. Nous pouvons vouloir copier du texte à partir d’une zone spécifique d’un PDF. De même, nous pouvons être amenés à utiliser ce texte à un stade ultérieur du traitement du PDF. Eh bien, nous avons la solution parfaite pour vous. Les actions PDF4me Workflows répondent à toutes ces logiques de documents.
Utilisez l’action Extraction de texte de PDF4me Workflows pour automatiser le processus d’extraction des données textuelles des documents PDF. En outre, utilisez des étapes supplémentaires pour réutiliser ces données partiellement ou complètement à un stade ultérieur. Examinons un exemple de flux de travail dans lequel nous extrayons du texte d’un document PDF et l’utilisons ultérieurement pour renommer le fichier.
Comment extraire le texte d’un PDF pour le réutiliser ?
Sans intégration supplémentaire, vous pouvez configurer un Workflow pour extraire automatiquement le texte d’un PDF. Voyons, à l’aide d’un exemple de flux de travail, comment nous pouvons automatiser l’extraction et le renommage du texte d’un PDF.
Ajoutez un déclencheur pour lancer votre flux de travail
Ajoutez un déclencheur pour lancer votre automatisation. Actuellement, les flux de travail fournissent 2 déclencheurs. Dropbox et Google Drive. Par exemple, créons un déclencheur Dropbox.
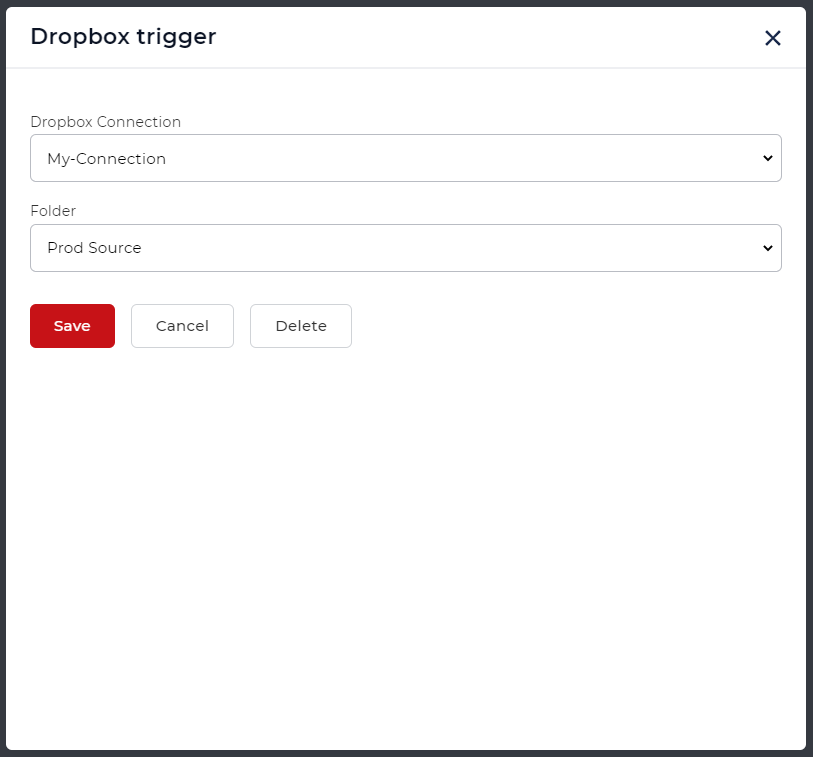
Configurez la connexion et choisissez le dossier où les fichiers d’entrée sont attendus.
Ajouter l’action Extraire le texte
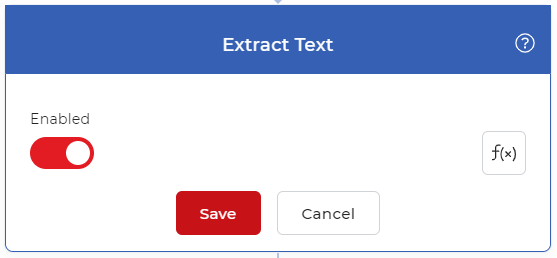
Ajouter l’action Extraction de texte et activer l’action. L’action extrait le texte complet du PDF. Si vous souhaitez extraire le texte de chaque page séparément, veuillez ajouter une action Split PDF avant l’action Extraire. Ajoutez également l’action Extraire le texte à l’intérieur du Contrôle pour chaque page.
Ajout d’une action de sauvegarde
Les fichiers de sortie devaient être sauvegardés sur un stockage en nuage. Dans notre cas d’utilisation, nous allons configurer une action Save to Dropbox. Vous pouvez utiliser une expression régulière pour obtenir un texte particulier à partir de l’action ‘Extraire le texte’. Vous pouvez copier-coller l’expression régulière ci-dessous dans le paramètre Nom du fichier de sortie et ajouter la condition pour faire correspondre le texte requis.
${file.pages[0].PageText.match(<condition>).pdf
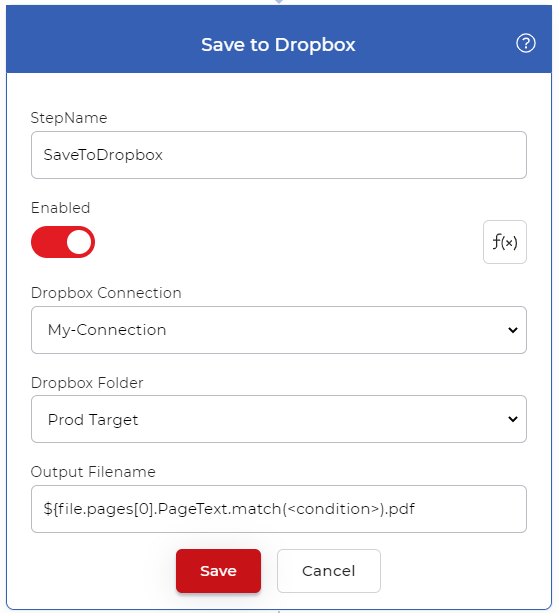
L’expression transmettra le texte correspondant à la condition du PDF et le transmettra au paramètre de nom de fichier de sortie afin que les fichiers soient renommés en fonction du texte lu.
Un échantillon à essayer
Examinons un flux de travail permettant d’extraire du texte d’un exemple de facture PDF et d’utiliser une partie spécifique du texte - le numéro de facture - pour renommer le fichier PDF avant de l’enregistrer sur le cloud.

Voyons brièvement les étapes -
- Ajoutez et configurez le déclencheur de votre choix
- Ajoutez l’action Extraction de texte et activez-la.
- Téléchargez l’exemple de facture PDF dans le dossier source du déclencheur - Télécharger le fichier échantillon{target=_blank}
- Ajoutez le stockage vers lequel vous voulez sauvegarder le fichier et dans le paramètre du nom du fichier de sortie, passez l’expression régulière suivante -
``${file.pages[0].PageText.match(‘INVOICE #(.*)’)[1].trim()}.pdf```
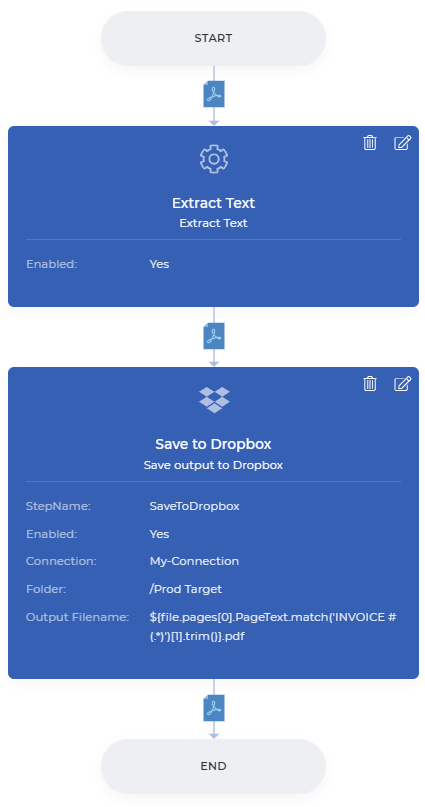
Le flux de travail ci-dessus va extraire le texte du PDF, couper la partie requise et renommer le fichier avec le même nom avant de l’enregistrer dans le stockage.
Pour avoir accès à Workflows, il vous faut un Abonnement PDF4me. Vous pouvez même obtenir un Daypass et essayer Workflows pour voir comment il peut vous aider à automatiser vos tâches documentaires.


