

用Zapier和PDF4me的PDF OCR来识别文本
有很多文件需要用OCR来识别和转换?我们捕获大量的文件图像或带有文本的表面,以提取数据或供以后参考。将扫描的文件或图像转换为可进行文本搜索的PDF文件对其进一步处理非常重要。为了使PDF可搜索,最常用的技术是光学字符识别 - OCR。
PDF4me提供高质量的PDF OCR,可以产生最准确的文本识别之一。但当你有数以百计的扫描文件需要被识别时,唯一的解决办法就是自动化。PDF4me也有这方面的解决方案。
与Zapier相结合,PDF4me可以将涉及到文档工作的业务流程自动化,这些流程是平凡而耗时的。PDF4me with Zapier将跨越数据源、应用程序和服务将您连接起来,轻松创建强大的工作流程,实现文档工作的自动化。
如何在Zapier中使用OCR?
让我们看一个例子,我们可以用Zapier中的PDF4me OCR动作将图像转换成PDF。假设我们在Google Drive中有一些文件图像或带有文本的图像,或者我们希望它们能到达一个特定的文件夹中。让我们把它们转换为PDF并执行OCR。
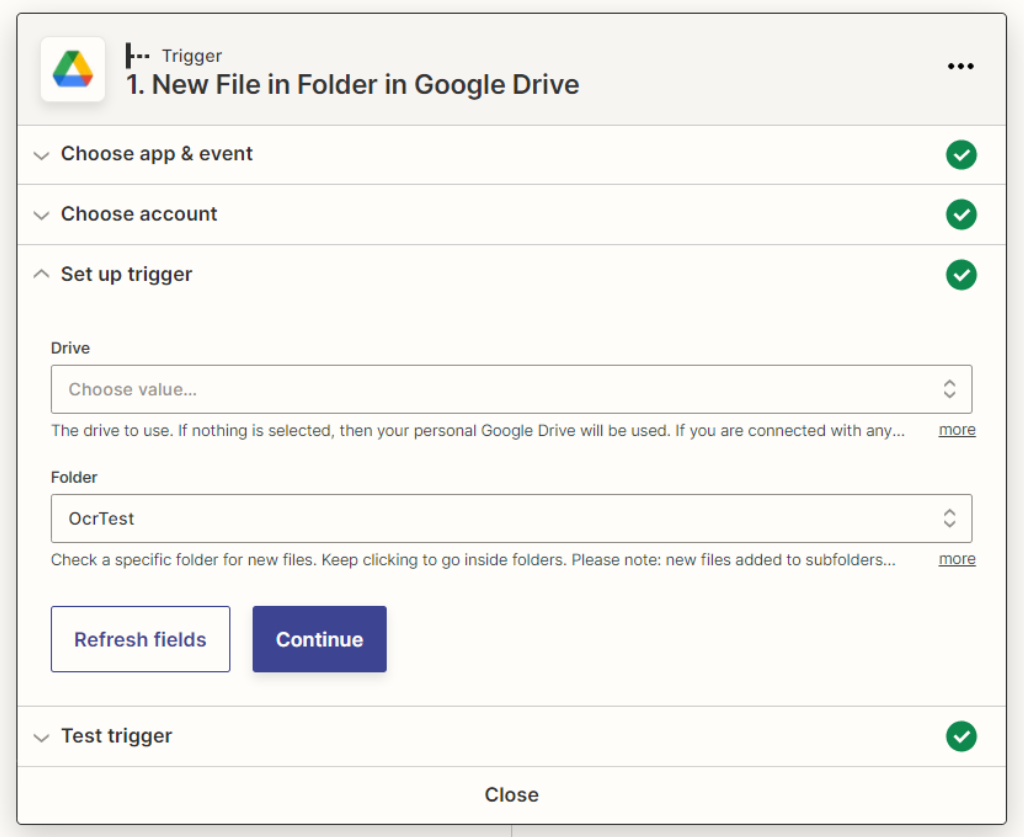
为谷歌驱动器添加一个触发器
Zapier有多种类型的触发器来启动你的工作流程。在这个用例中,添加一个Google Drive触发器来启动自动化。一旦文件夹中收到文件,Zap就会被这个动作触发。
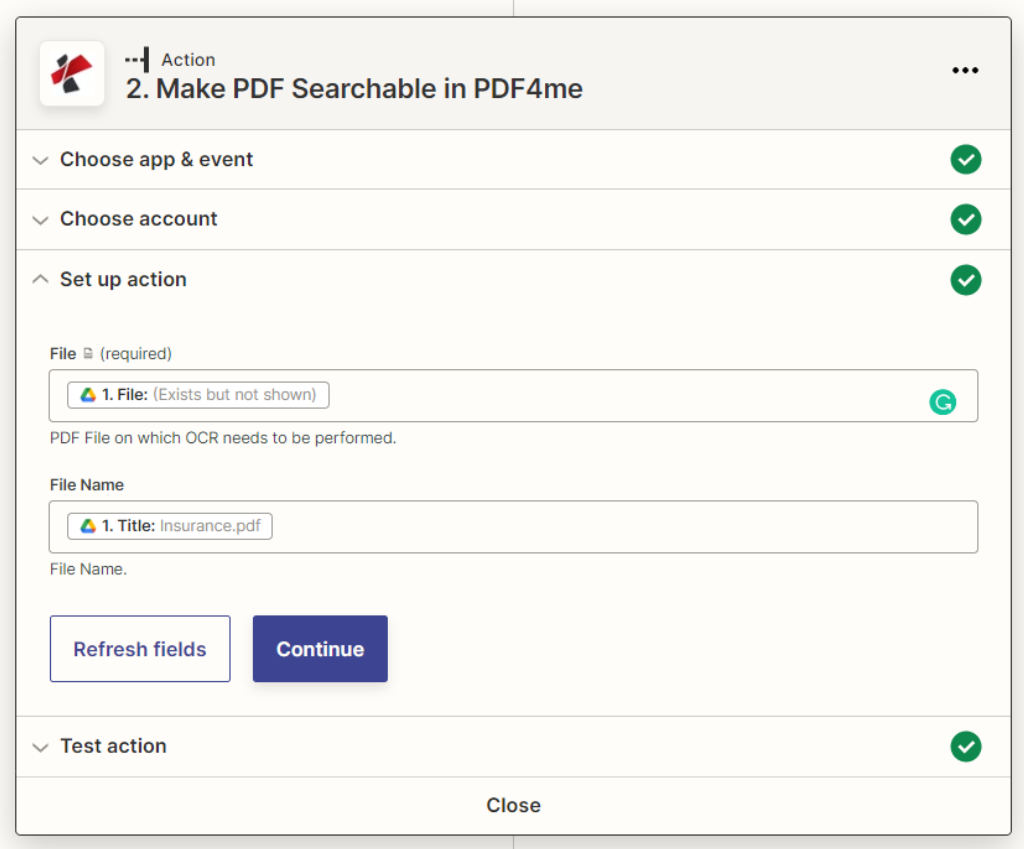
添加和配置PDF OCR动作
从PDF4me行动中,列出选择PDF OCR。
**文件内容:**从源行动中输入文件内容
**文件名:**从源行动中输入文件内容
**质量类型:**选择质量类型。草稿或高
PDF4me推荐高质量档案的图像OCR,它确保即使从复杂的图像中也能准确识别。
将 "仅在需要时进行OCR "设置为true,这样该动作就不会对已经被识别的PDF执行OCR。从而,节省了调用成本。
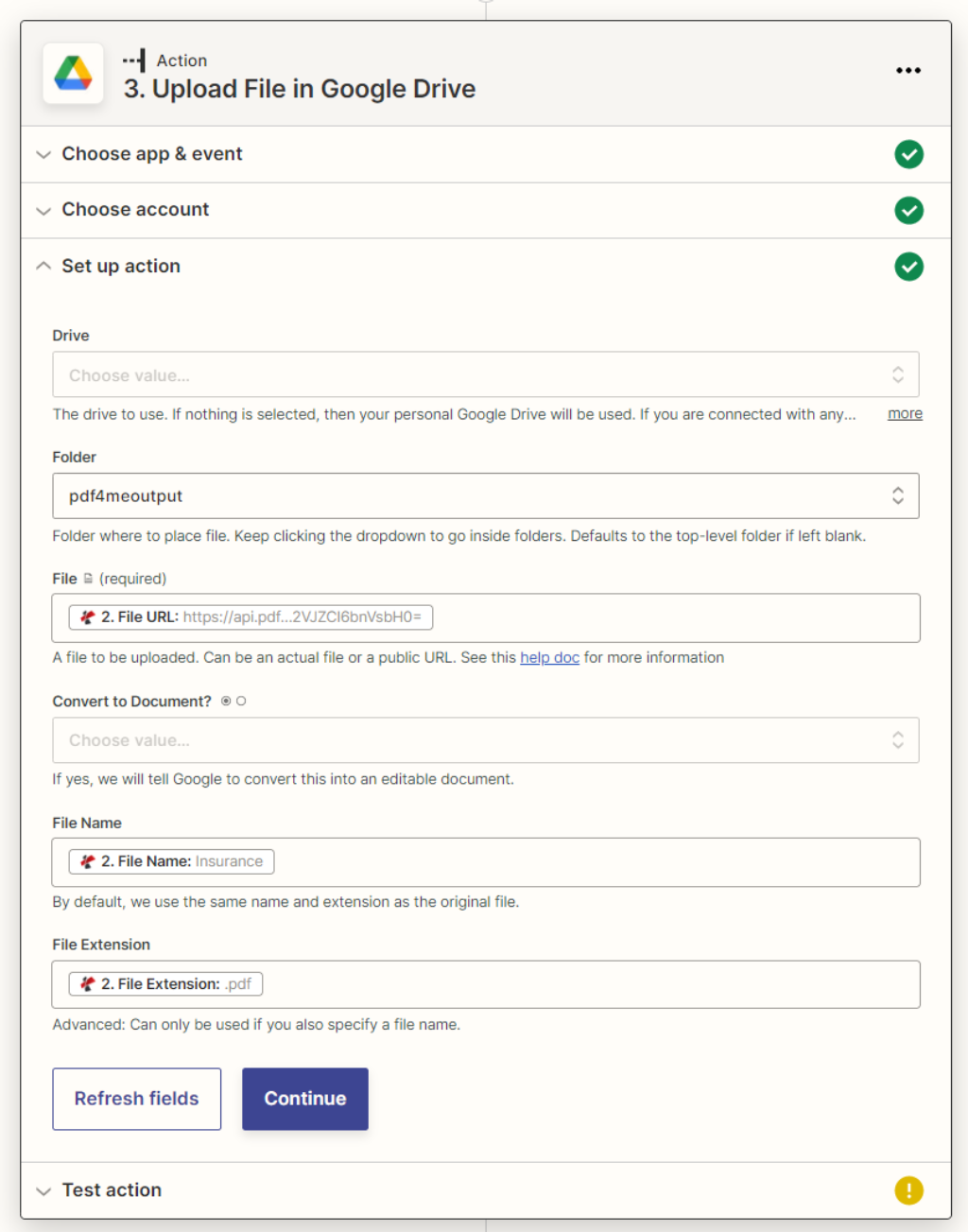
保存OCR处理的文件
最后,在OCR动作之后添加一个动作,将输出的PDF文件存储到所需的存储器中。在这个例子中,我们再次使用Google Drive的保存动作。
使用PDF4me 开发者订阅,创建PDF OCR工作流程和更多令人敬畏的自动化,节省宝贵的时间,专注于最重要的事情。


