

使用PDF4me工作流程用PDF OCR识别文本
将扫描的文件或图像转化为文本可搜索的PDF文件,对进一步处理这些文件很重要。为了使PDF可搜索,所使用的技术是光学字符识别 - OCR。对于商业和企业来说,可能有大量的文件需要处理。这就要求实现PDF OCR的自动化。
PDF4me提供高质量的PDF OCR,可以产生最准确的文本识别之一。但当你有数以百计的扫描文件需要被识别时,唯一的解决办法就是自动化。PDF4me Workflows有一个完美的行动来执行这种自动化 - PDF OCR。
如何使用工作流程自动处理PDF OCR
从扫描的文件或带有文本的图像创建可搜索的PDF文件。该操作使你能从输出的PDF中搜索或复制文本。
让我们看看一个带有PDF OCR动作的工作流程样本。首先从[工作流程仪表板](/pdf4me-workflows/dashboard/)中选择创建工作流程。
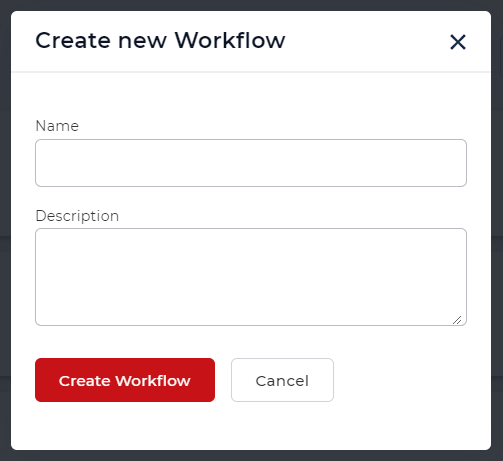
为工作流添加一个触发器
创建和配置一个触发器来启动工作流自动化。一旦有新的文件到达触发器中配置的文件夹中,自动化就会被初始化。
让我们用Google Drive的触发器为例。
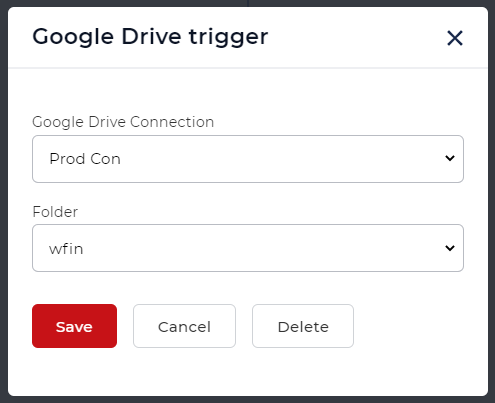
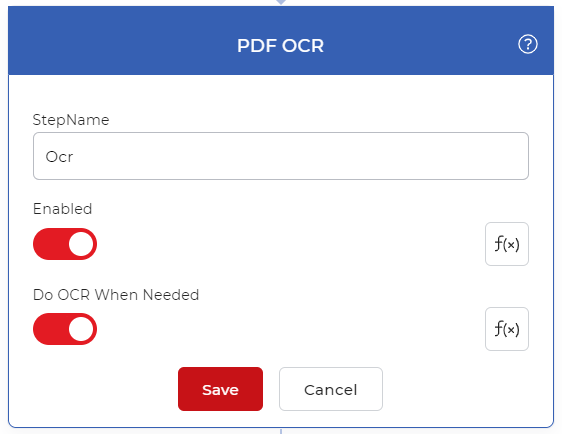
添加PDF OCR动作
添加ODF OCR动作并启用 “需要时做OCR”,以确保OCR只在需要时使用,以节省不必要的调用。
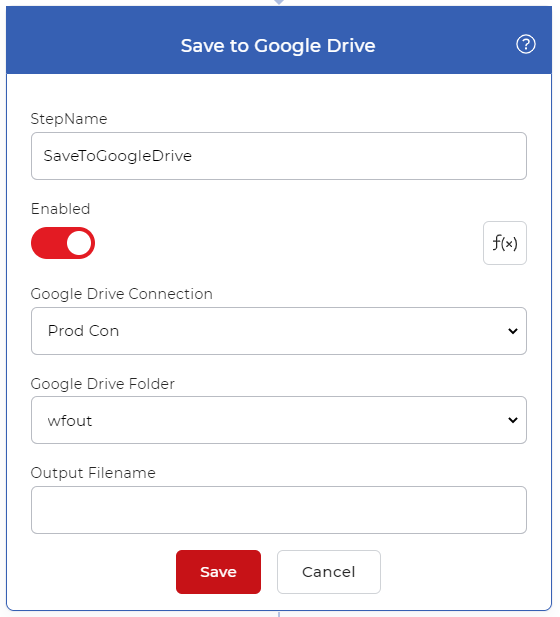
添加保存到存储
添加保存输出文件的操作。我们可以选择保存到Google Drive为例。配置你希望保存处理后的文件的文件夹。
一旦配置完成,你可以保存以发布工作流程。一个工作流程的样本看起来如下。
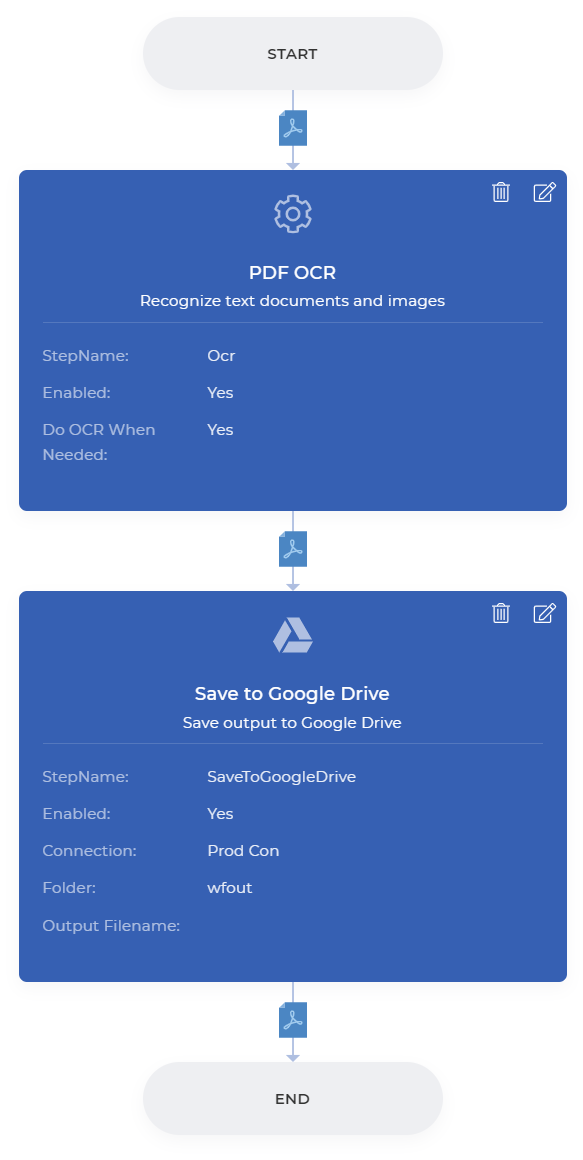
要访问**工作流程,你需要一个[PDF4me订阅](/zh-hans/pricing/)。你甚至可以得到一个Daypass并尝试使用Workflows,看看它如何帮助你的文件工作自动化。


