

使用Power Automate和PDF4me从PDF中提取页面
我们经常会遇到很多大文件,而我们只需要其中的少数信息。一些PDF文件,如合同,法律文件,或数字书籍可能包含数百或数千页。有时,我们可能只需要这些文件中的几页。在这种情况下,我们将不得不使用一个特定的工具来提取这些PDF页面。但所有的软件服务都能做到这一点。
现在你可以使用PDF4me的Extract Pages动作自动从PDF文档中提取特定页面。使用PDF4me Connect integration for Power Automate中的动作来创建流程,以实现这一过程的自动化。通过简单的配置和零编码,你可以轻松设置提取PDF页面的流程。
如何自动从PDF中提取页面?
通过使用这一功能,可以将文档的页面分离出来并进一步处理。 让我们通过一个示例流程,看看我们如何构建一个流程来自动提取PDF页面。
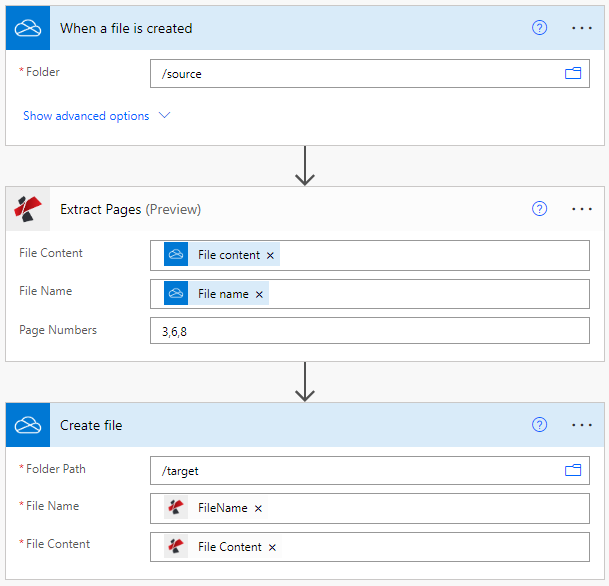
为流量添加一个触发器
你可以添加任何选择的触发器,将输入的PDF文档传递给PDF4me的提取动作。在这种情况下,让我们添加并配置一个Onedrive触发器。映射出你期望PDF文件到达的文件夹。
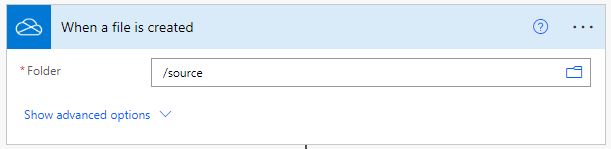
添加从PDF中提取页面的动作
添加并配置PDF4me Connect动作为从PDF中提取页面。指定你想从源PDF中提取的页面的页码。
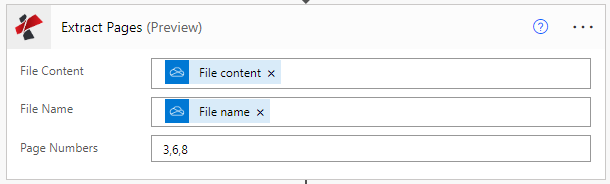
添加动作以保存输出
由于我们已经开始使用Onedrive存储,让我们添加Onedrive 创建文件动作,以保存使用从源文件提取的页面创建的PDF。
通过PDF4me Developer Subscription,您可以在Power Automate中创建流程,能够以较低的成本实现**从PDF中提取页面的自动化。该订阅确保你的自动化永远不会因为API调用的数量不足而停止。现在就注册并开始免费试用。


