

Escanear y dividir PDF por texto específico contenido en ellos
Hoy en día automatizamos muchos procesos documentales. ¿Quiere reconocer un texto específico de un PDF? ¿Quiere utilizar ese texto para dividir el archivo en las páginas que contienen el texto específico? ¿Quiere renombrar los archivos divididos usando el texto utilizado para la división? Bueno, tenemos la solución perfecta para usted.
La acción PDF4me Workflows Split By Text se ocupa de toda esa lógica de los documentos. Los flujos de trabajo se centran exclusivamente en ofrecer la mejor solución de automatización para sus procesos documentales. La acción también puede almacenar el texto en el portapapeles para renombrar los archivos con el texto si es necesario mientras se guarda en el almacenamiento. Veamos ahora con un ejemplo de flujo de trabajo, cómo podemos configurar esta acción.
¿Cómo escanear y dividir un PDF por un texto específico?
En nuestro siguiente ejemplo, crearemos un flujo de trabajo para dividir un archivo PDF utilizando un texto específico contenido en él y utilizaremos el texto para renombrar los archivos divididos.
Comience por lanzar el PDF4me Dashboard.
- Seleccione el botón Crear flujo de trabajo.
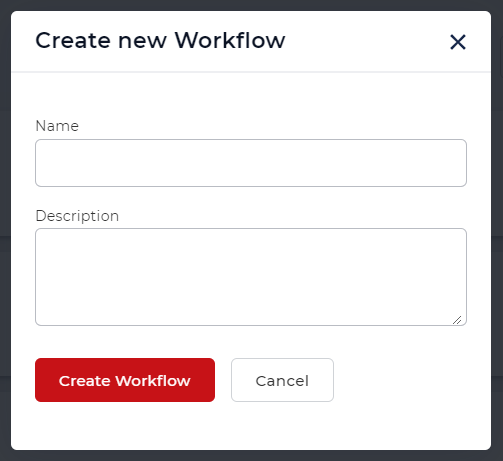
Añada un activador para iniciar su flujo de trabajo
Añada un activador para poner en marcha su automatización.
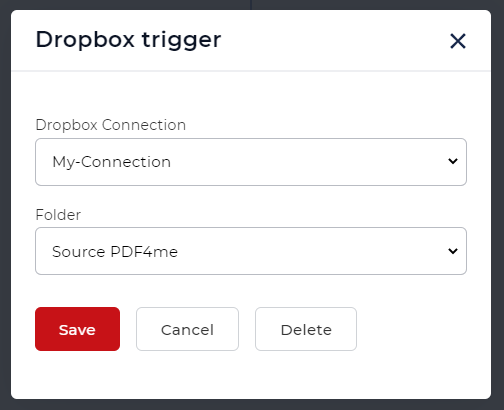
- Actualmente, los flujos de trabajo proporcionan 2 disparadores - Dropbox y Google Drive. Por ejemplo, vamos a crear un disparador de Dropbox.
Configure la conexión y elija la carpeta donde se esperan los archivos de entrada.
Para probar el flujo exacto, puede hacer uso de este PDF de muestra - Descargar archivo de muestra
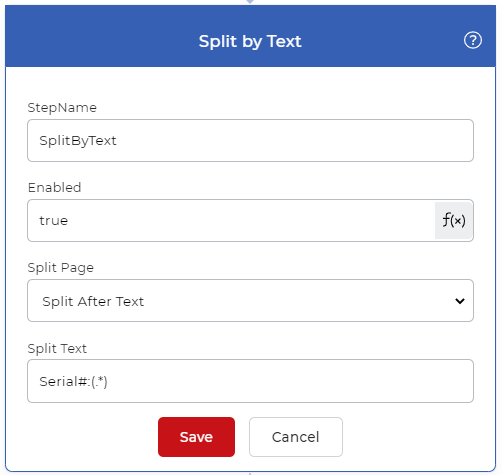
Añadir la acción Dividir por texto
Añada y configure una acción Dividir por texto para separar las páginas del archivo utilizando el texto requerido. Aquí utilizamos una expresión regular para detectar el texto único.
Serial#:(.*)
La regex encontrará el valor del texto que comienza con ‘Serial#:’ y lo dividirá en base a la condición.
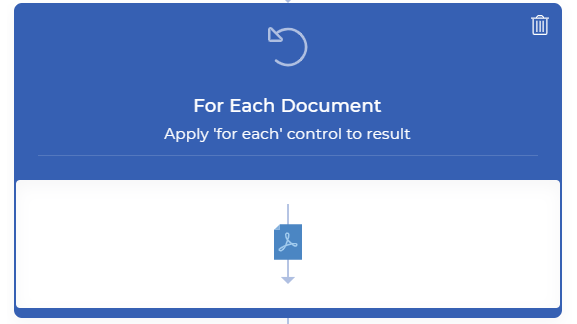
Añadir un control para cada documento
Dado que el Split By Text genera múltiples documentos, es necesario un control For Each Document para manejar los archivos de salida uno por uno. El resto de las acciones deben incluirse dentro de este control.
Añadir una acción de guardar
Los archivos de salida deben ser guardados en la nube. En nuestro caso de uso vamos a configurar una acción Guardar en Dropbox. En la imagen de arriba, puede ver una expresión para obtener un texto de la acción ‘Dividir por texto’. Puede utilizar la expresión regular dada a continuación en el parámetro Output File Name para renombrar los archivos.
${file.pages[0].PageText}.pdf
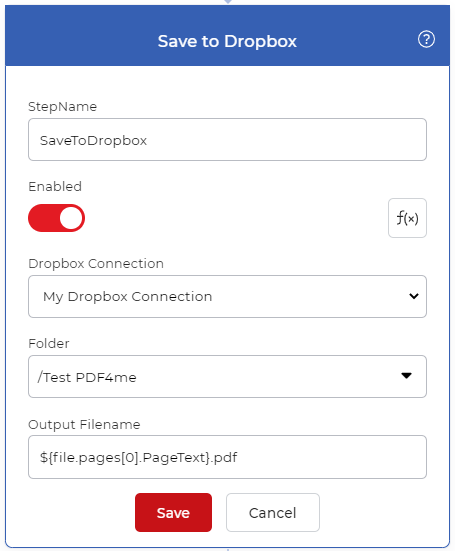
La expresión pasará el texto de la acción Dividir por PDF al parámetro de nombre de archivo de salida para que los archivos sean renombrados en base al texto leído.
Para obtener acceso a Flujos de trabajo se requiere una Suscripción a PDF4me. Incluso puede obtener un Daypass y probar Workflows para ver cómo puede ayudar a automatizar sus trabajos documentales.


