

从PDF中提取文本并在以后使用工作流程重新使用它
数字文件正在快速取代传统的纸质文件。如今,我们收到了很多的PDF文件。像合同、法律文件或数字书籍的PDF文件可能包含数百或数千页。我们对这些文件进行了大量的自动化处理。我们可能想从一个PDF的特定区域复制文本。而且,我们可能要在以后处理PDF的时候使用这些文本。那么,我们为你提供了完美的解决方案。PDF4me工作流程满足了所有这些文件的逻辑。
使用PDF4me Workflows中的Extract Text动作,可以自动从PDF文档中提取文本数据的过程。此外,使用额外的步骤,在以后的阶段部分或完全重新使用这些数据。让我们看看一个工作流程样本,我们从一个PDF文档中提取文本,并在以后使用它来重命名文件。
如何从PDF中提取文本以便再利用?
不需要额外的整合,你可以配置一个工作流来自动提取PDF中的文本。让我们通过一个工作流程样本,看看我们如何能够自动提取和重命名PDF文本。
添加一个触发器来启动你的工作流
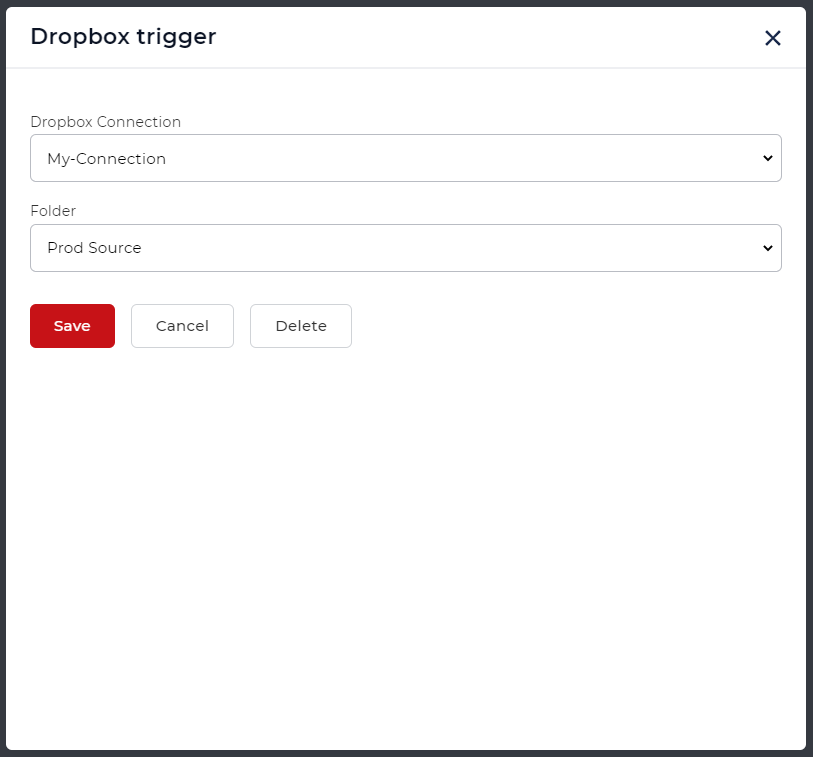
添加一个触发器来启动你的自动化。目前,工作流程提供2个触发器。Dropbox和Google Drive。例如,让我们创建一个Dropbox触发器。
配置连接,并选择预期输入文件的文件夹。
添加提取文本动作
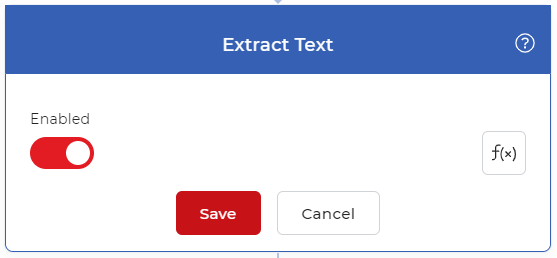
添加提取文本动作并启用该动作。这个动作会从PDF中提取全文。如果你想从每一页单独提取,请在提取动作之前添加一个分割PDF动作。同时,在**每个控件的内部添加提取文本的动作。
添加一个保存行动
输出的文件需要被保存到云存储。在我们的用例中,让我们配置一个保存到Dropbox的动作。你可以使用正则表达式从 "提取文本 "动作中获取一个特定的文本。你可以在输出文件名参数中复制粘贴以下相同的正则表达式,并添加条件以匹配所需的文本。
${file.pages[0].PageText.match(<condition>).pdf
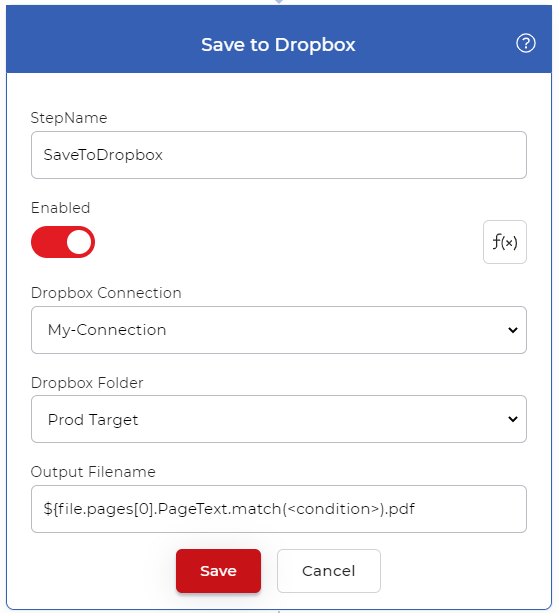
该表达式将从PDF中传递符合条件的文本,并将其传递给输出文件名参数,以便根据读取的文本对文件进行重命名。
试用的样品
让我们看看一个工作流程,从样本发票PDF中提取文本,并使用文本的特定部分–发票号码–在保存到云端之前重命名PDF文件。

让我们简要地看一下步骤–
1.添加并配置你选择的触发器
2.添加提取文本动作并启用它。
3.在触发器的源文件夹中上传PDF发票样本 - 下载样本文件{target=_blank}
4.
``${file.pages[0].PageText.match(‘INVOICE #(.*)’)[1].trim()}.pdf````。
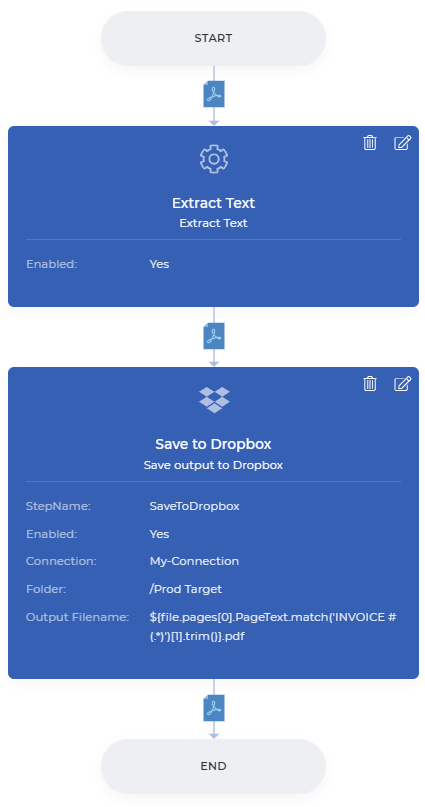
上述工作流程将从PDF中提取文本,修剪所需的部分,并在将其保存到存储器之前用相同的内容重命名该文件。
要访问**工作流程,你需要一个[PDF4me订阅](/zh-hans/pricing/)。你甚至可以得到一个Daypass并尝试使用Workflows,看看它如何帮助你的文件工作自动化。


